Download the notebook here
First Method of Simulated Moments (MSM) estimation with estimagic¶
This tutorial shows how to do a Method of Simulated Moments estimation in estimagic. The Method of Simulated Moments (MSM) is a nonlinear estimation principle that is very useful to fit complicated models to data. The only thing that is needed is a function that simulates model outcomes that you observe in some empirical dataset.
The tutorial uses an example model from Rick Evans’ great tutorial on MSM. The model is deliberately simple so we can focus on the mechanics of the MSM estimation.
Throughout the tutorial we only talk about MSM estimation, however, the more general case of indirect inference estimation works exactly the same way.
Steps of MSM estimation¶
load empirical data
define a function to calculate estimation moments on the data
calculate the covariance matrix of the empirical moments (with
get_moments_cov)define a function to simulate moments from the model
estimate the model, calculate standard errors, do sensitivity analysis (with
estimate_msm)
Example: Estimating the parameters of a truncated normal distribution¶
The model we consider is a truncated normal distribution. The goal is to estimate its parameters from a dataset of grades observed in a macroeconomics class.
The estimation mechanics are exactly the same for more complicated models. A model is always defined by a function that can take parameters (here: the mean, variance and lower_cutoff and upper_cutoff) and returns a number of simulated moments (mean, variance, soft_min and soft_max of simulated exam points).
[1]:
import numpy as np
import pandas as pd
from estimagic.config import EXAMPLE_DIR
Load data¶
[2]:
data = pd.read_csv(EXAMPLE_DIR / "exam_points.csv")
data.head(3).append(data.tail(3))
[2]:
| points | |
|---|---|
| 0 | 275.50 |
| 1 | 351.50 |
| 2 | 346.25 |
| 158 | 112.30 |
| 159 | 130.60 |
| 160 | 60.20 |
Define function to calculate moments¶
Deciding which moments to use in the estimation is the most difficult part of any MSM estimation.
Below we list the parameters we want to estimate and moments we hope are informative to identify those parameters:
Moment |
Parameters |
|---|---|
mean |
mean |
sd |
sd |
min |
lower_trunc |
max |
upper_trunc |
Note that such a direct equivalence of moments and parameters is not strictly needed, but it is a good way to think about the problem:
We can also estimate a version where we only use the first two moments or we could include even more moments (like shares that fall into a certain bin of points, as in Rick’s original example). In general, more moments are better.
[3]:
def calculate_moments(sample, targets="all"):
points = sample["points"]
moments = {
"mean": sample.mean()[0],
"sd": sample.std()[0],
"min": sample.min()[0],
"max": sample.max()[0],
}
if targets != "all":
moments = {k: v for k, v in moments.items() if k in targets}
moments = pd.Series(moments)
return moments
[4]:
empirical_moments = calculate_moments(data)
empirical_moments
[4]:
mean 341.908696
sd 88.752027
min 17.000000
max 449.800000
dtype: float64
Calculate the covariance matrix of empirical moments¶
The covariance matrix of the empirical moments (moments_cov) is needed for three things: 1. to calculate the weighting matrix 2. to calculate standard errors 3. to calculate sensitivity measures
We will calculate moments_cov via a bootstrap. Depending on your problem there can be other ways to do it.
[5]:
from estimagic import get_moments_cov
[6]:
moments_cov = get_moments_cov(
data, calculate_moments, bootstrap_kwargs={"n_draws": 5_000, "seed": 1234}
)
moments_cov
[6]:
| mean | sd | min | max | |
|---|---|---|---|---|
| mean | 46.350178 | -39.636378 | 24.722806 | 2.244858 |
| sd | -39.636378 | 57.844397 | -42.619581 | 0.039351 |
| min | 24.722806 | -42.619581 | 208.501435 | 2.444657 |
| max | 2.244858 | 0.039351 | 2.444657 | 11.608600 |
get_moments_cov mainly just calls estimagic’s bootstrap function. See our bootstrap_tutorial for background information.
Define a function to calculate simulated moments¶
In a real application, this is the step that takes most of the time. However, in our very simple example, all the work is already done by scipy.
To test our function let’s first set up a parameter vector (which will also serve as start parameters for the numerical optimization).
[7]:
params = pd.DataFrame(
[500, 100, 0, 450],
index=["mean", "sd", "lower_trunc", "upper_trunc"],
columns=["value"],
)
params["lower_bound"] = [-np.inf, 0, -np.inf, -np.inf]
params
[7]:
| value | lower_bound | |
|---|---|---|
| mean | 500 | -inf |
| sd | 100 | 0.0 |
| lower_trunc | 0 | -inf |
| upper_trunc | 450 | -inf |
[8]:
from scipy.stats import truncnorm
[9]:
def simulate_moments(params, n_draws=1_000, seed=5471):
np.random.seed(seed)
pardict = params["value"].to_dict()
draws = truncnorm.rvs(
a=(pardict["lower_trunc"] - pardict["mean"]) / pardict["sd"],
b=(pardict["upper_trunc"] - pardict["mean"]) / pardict["sd"],
loc=pardict["mean"],
scale=pardict["sd"],
size=n_draws,
)
sim_data = pd.DataFrame()
sim_data["points"] = draws
sim_moments = calculate_moments(sim_data)
return sim_moments
[10]:
simulate_moments(params)
[10]:
mean 384.237035
sd 53.591526
min 66.218431
max 449.943485
dtype: float64
Estimate the model parameters¶
Estimating a model consists of the following steps:
Building a criterion function that measures a distance between simulated and empirical moments
Minimizing this criterion function
Calculating the Jacobian of the model
Calculating standard errors, confidence intervals and p values
Calculating sensitivity measures
This can all be done in one go with the estimate_msm function. This function has good default values, so you only need a minimum number of inputs. However, you can configure almost every aspect of the workflow via optional arguments. If you need even more control, you can call the low level functions estimate_msm is built on directly.
[11]:
from estimagic import estimate_msm
[12]:
res = estimate_msm(
simulate_moments,
empirical_moments,
moments_cov,
params,
optimize_options={"algorithm": "scipy_lbfgsb"},
)
[13]:
res["summary"]
[13]:
| value | standard_error | p_value | ci_lower | ci_upper | stars | |
|---|---|---|---|---|---|---|
| mean | 631.877928 | 258.699593 | 0.014294 | 124.836043 | 1138.919812 | ** |
| sd | 198.079074 | 78.350939 | 0.011239 | 44.514054 | 351.644093 | ** |
| lower_trunc | 16.754463 | 14.435138 | 0.240860 | -11.537887 | 45.046813 | |
| upper_trunc | 449.887000 | 3.414019 | 0.000000 | 443.195646 | 456.578354 | *** |
What’s in the result?¶
The result is a dictionary with the following entries:
[14]:
res.keys()
[14]:
dict_keys(['summary', 'cov', 'sensitivity', 'jacobian', 'optimize_res', 'jacobian_numdiff_info'])
summary: A DataFrame with estimated parameters, standard errors, p_values and confidence intervals. This is ideal for use with our
estimation_tablefunction.cov: A DataFrame with the full covariance matrix of the estimated parameters. You can use this for hypothesis tests.
optimize_res: A dictionary with the complete output of the numerical optimization (if one was performed)
numdiff_info: A dictionary with the complete output of the numerical differentiation (if one was performed)
jacobian: A DataFrame with the jacobian of
simulate_momentswith respect to the free parameters.sensitivity: A dictionary of DataFrames with the six sensitivity measures from Honore, Jorgensen and DePaula (2020)
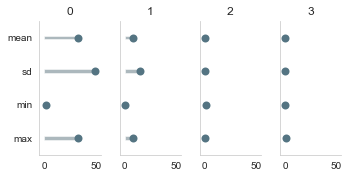
How to visualize sensitivity measures¶
For more background on the sensitivity measures and their interpretation, check out the how to guide on sensitivity measures.
Here we are just showing you how to plot them:
[15]:
from estimagic.visualization.lollipop_plot import lollipop_plot
lollipop_plot(res["sensitivity"]["sensitivity_to_bias"].abs().T);
How to deal with calibrated parameters¶
In many MSM applications, not all parameters are estimated freely. Instead, some of them are calibrated outside of the model. Thus, they are fixed during the estimation and no standard errors can be calculated for them.
To do this in estimate_msm, you can use the same constraint syntax you already know from maximize and minimize.
For example, in Rick’s Tutorial, the cutoffs are fixed to 0 and 450, respectively. This can be expressed as follows:
[16]:
constraints = [
{"loc": "lower_trunc", "type": "fixed", "value": 0},
{"loc": "upper_trunc", "type": "fixed", "value": 450},
]
res_small = estimate_msm(
simulate_moments,
empirical_moments,
moments_cov,
params,
optimize_options={"algorithm": "scipy_lbfgsb"},
constraints=constraints,
)
res_small["summary"]
[16]:
| value | standard_error | p_value | ci_lower | ci_upper | stars | |
|---|---|---|---|---|---|---|
| mean | 595.467999 | 194.073229 | 0.002110 | 215.091460 | 975.844537 | *** |
| sd | 186.593618 | 63.451907 | 0.003209 | 62.230166 | 310.957069 | *** |
| lower_trunc | 0.000000 | NaN | NaN | NaN | NaN | NaN |
| upper_trunc | 450.000000 | NaN | NaN | NaN | NaN | NaN |
[17]:
lollipop_plot(
[
res["sensitivity"]["sensitivity_to_bias"].abs().T,
res_small["sensitivity"]["sensitivity_to_bias"].abs().T,
]
);

Calculating standard errors, p values for the constrained model works out of the box. The sensitivity measures for free parameters also work. Showing sensitivity of estimated parameters with respect to calibrated ones does not work yet but is planned soon. If you can’t wait, check out Thomas Jorgensen’s Paper on the topic and make a pull request ;-)
Comparison with Rick’s results¶
We can compare point estimates and standard errors to Rick’s Maximum Likelihood and MSM estimates. Note that he fixed the lower and upper truncation points.
[18]:
comparison = pd.DataFrame()
comparison["estimagic_free"] = res["optimize_res"]["solution_params"][["value"]].round(
1
)
comparison["estimagic_fixed"] = res_small["optimize_res"]["solution_params"][
["value"]
].round(1)
comparison["rick_mle"] = [622.3, 198.8, 0, 450]
comparison["rick_msm"] = [612.3, 197.3, 0, 450]
comparison
[18]:
| estimagic_free | estimagic_fixed | rick_mle | rick_msm | |
|---|---|---|---|---|
| mean | 631.9 | 595.5 | 622.3 | 612.3 |
| sd | 198.1 | 186.6 | 198.8 | 197.3 |
| lower_trunc | 16.8 | 0.0 | 0.0 | 0.0 |
| upper_trunc | 449.9 | 450.0 | 450.0 | 450.0 |
Interestingly, the estimates where all parameters are free are closer to the maximum likelihood estimates than the other ones.
Note that we used different estimation moments, so the results are not really comparable. We will do an exact replication soon.