Introduction to basic types of numerical optimization algorithms#
There are hundreds of different numerical optimization algorithm. However, most of them build on a few basic principles. Knowing those principles helps to classify algorithms and thus allows you to connect information about new algorithms with the stuff you already know.
The main principles we describe here are:
Derivative based line search algorithms
Derivative based trust region algorithms
Derivative free trust region algorithms
Derivative free direct search algorithms
This covers a large range of the algorithms that come with estimagic. We do currently not cover:
Conjugate gradient methods
Genetic algorithms
Grid or random search
Bayesian Optimization
For each class of algorithms we describe the basic idea, show a gif of a stylized implementation with a graphical explanation of each iteration and a gif that shows how a real algorithm of the class converges.
All of the above algorithms are local optimization algorithms that can (and will in fact) get stuck in local optima. If you need a global optimum, you will need to start them from several starting points and take the best result.
Derivative based line search algorithms#
Basic idea#
Use first derivative to get search direction
Use approximated second derivative to guess step length
Use a line search algorithm to see how far to go in the search direction
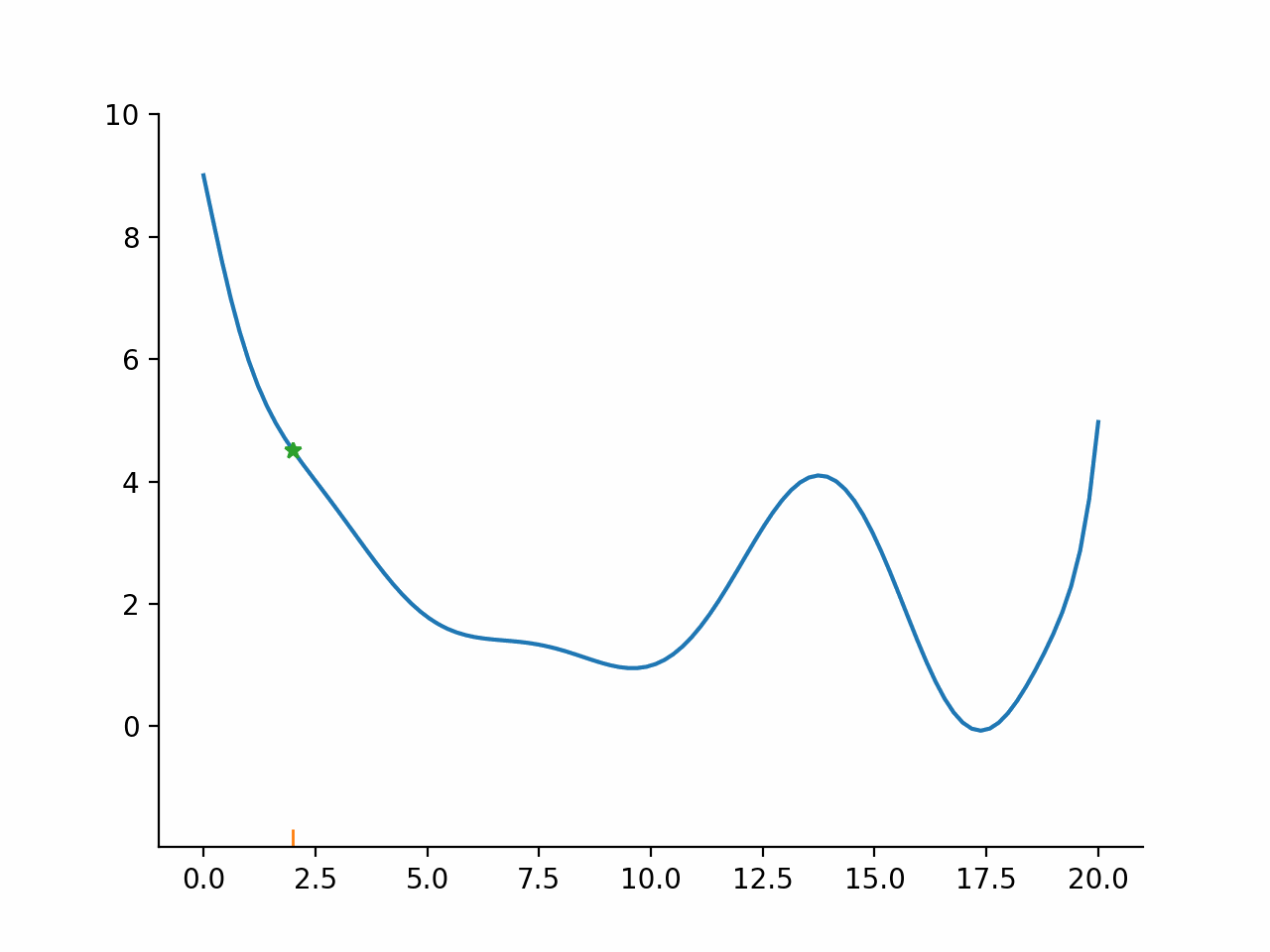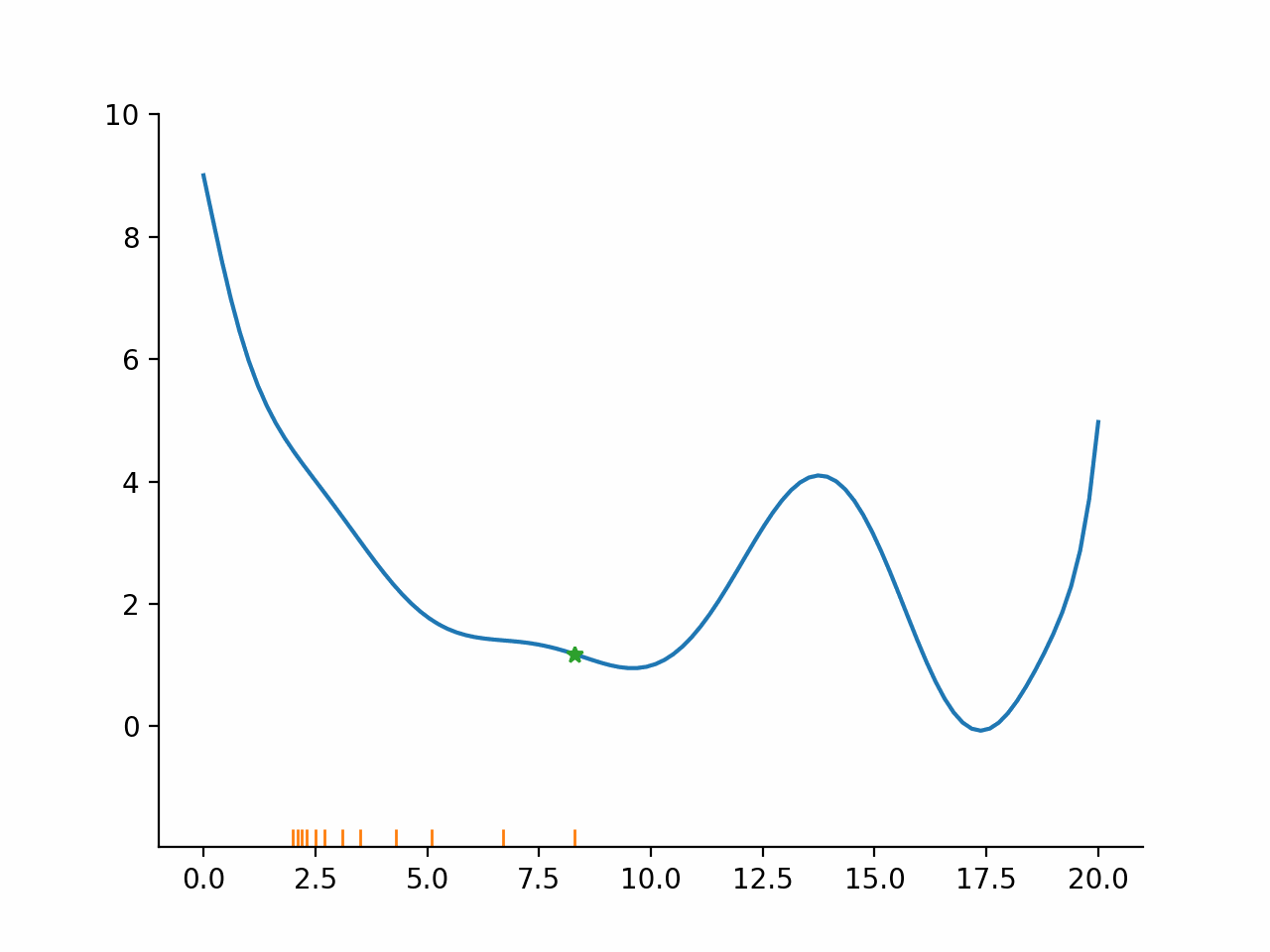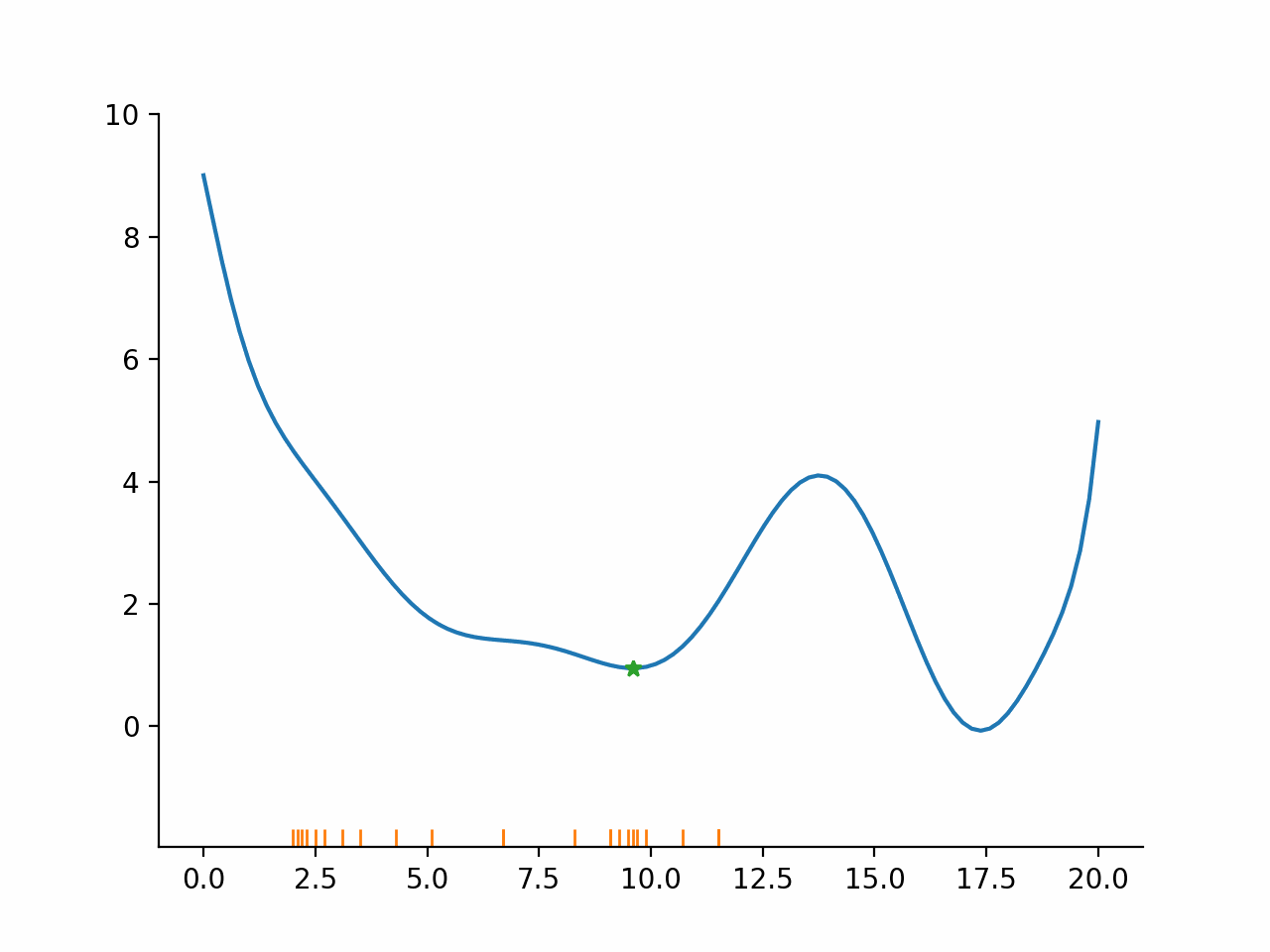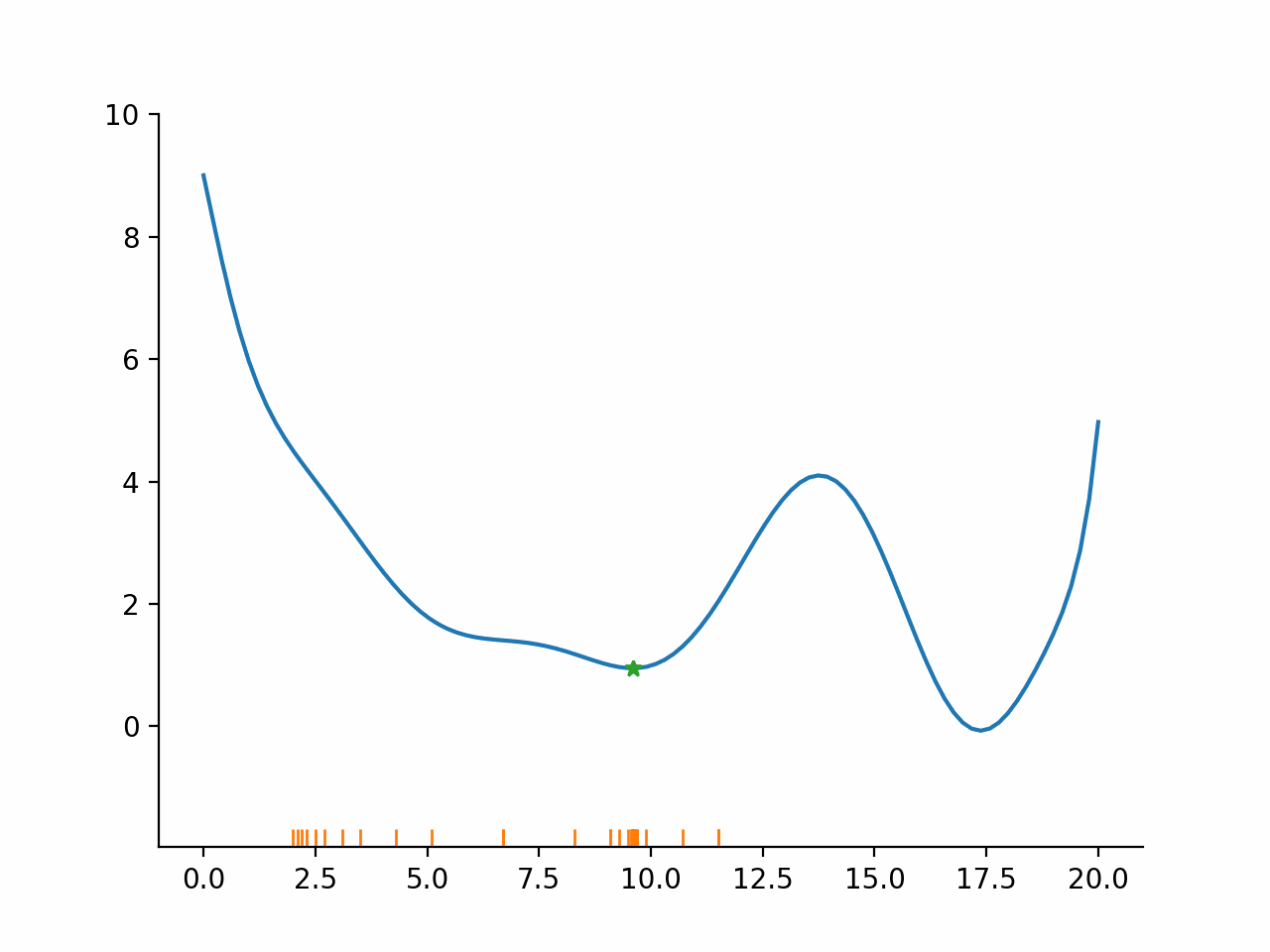
In other words, the algorithm first fixes a promising direction and then figures out how far it should go in that direction. The important insight here is that even though the parameter space might be high dimensional, the line search problem remains one dimensional and thus simple to solve. Moreover, the line search problem is typically not solved exactly but only approximately. The exact termination conditions for the line search problem are complicated, but most of the time the initial guess for the step length is accepted.
Stylized implementation#
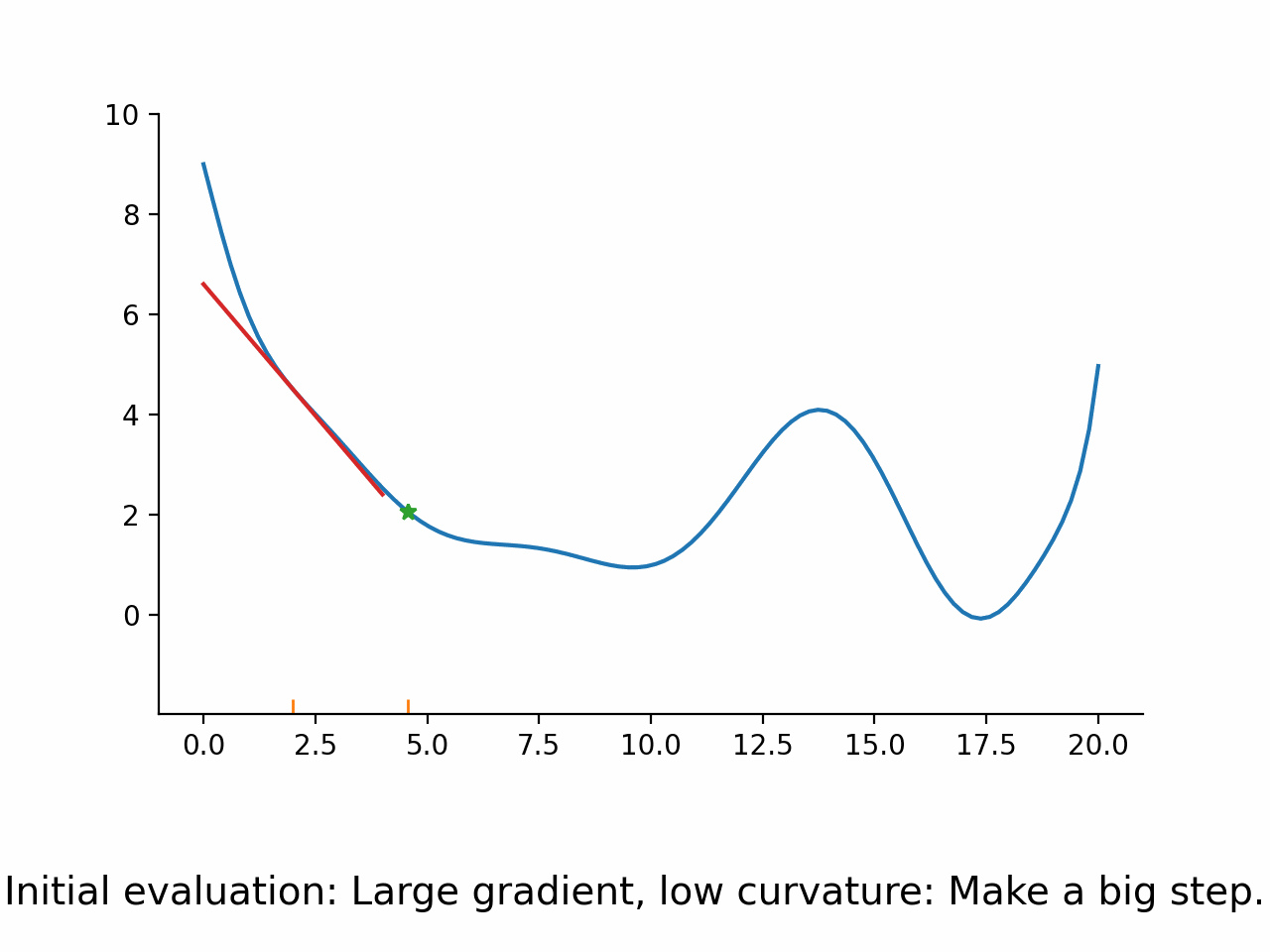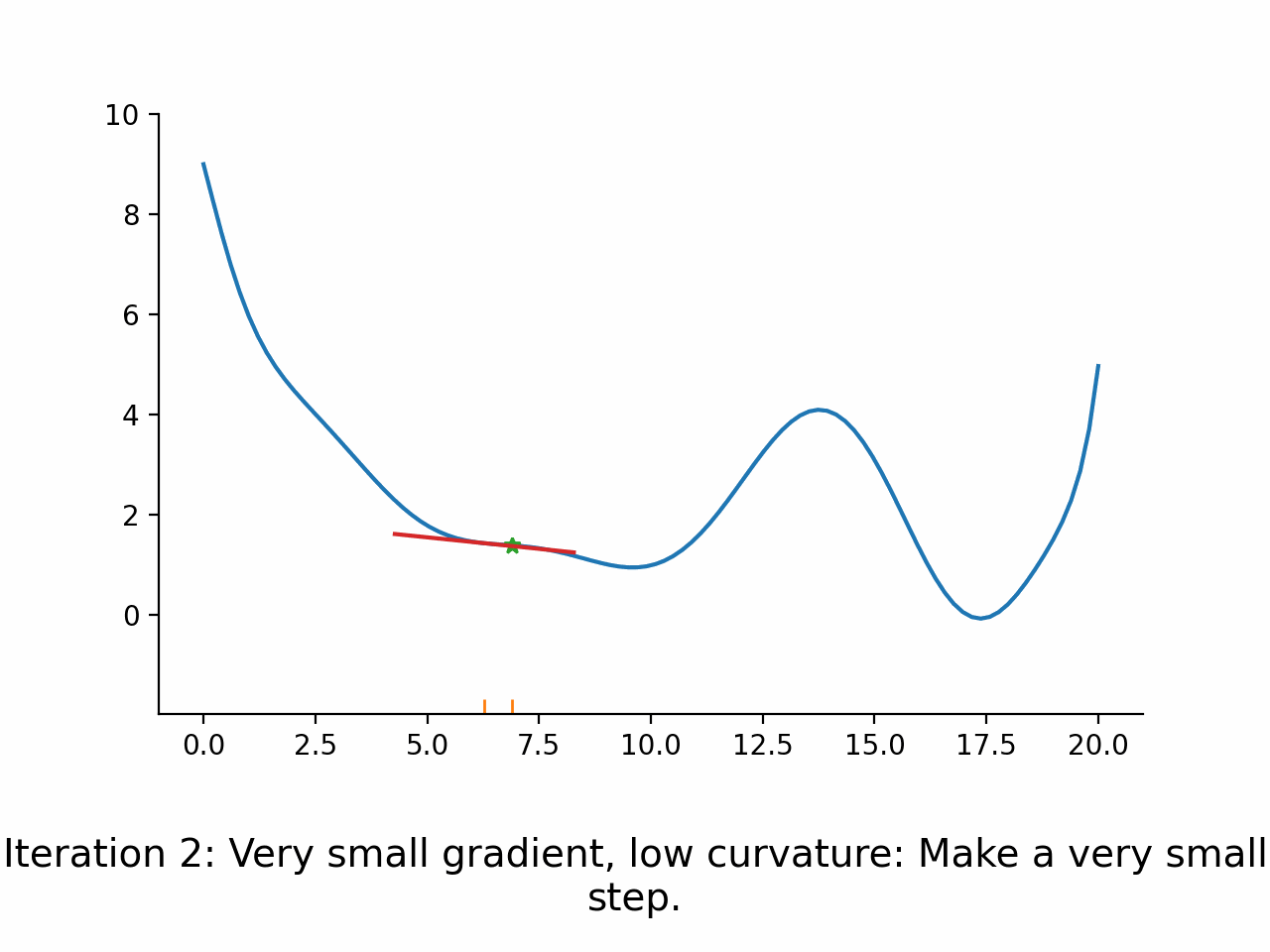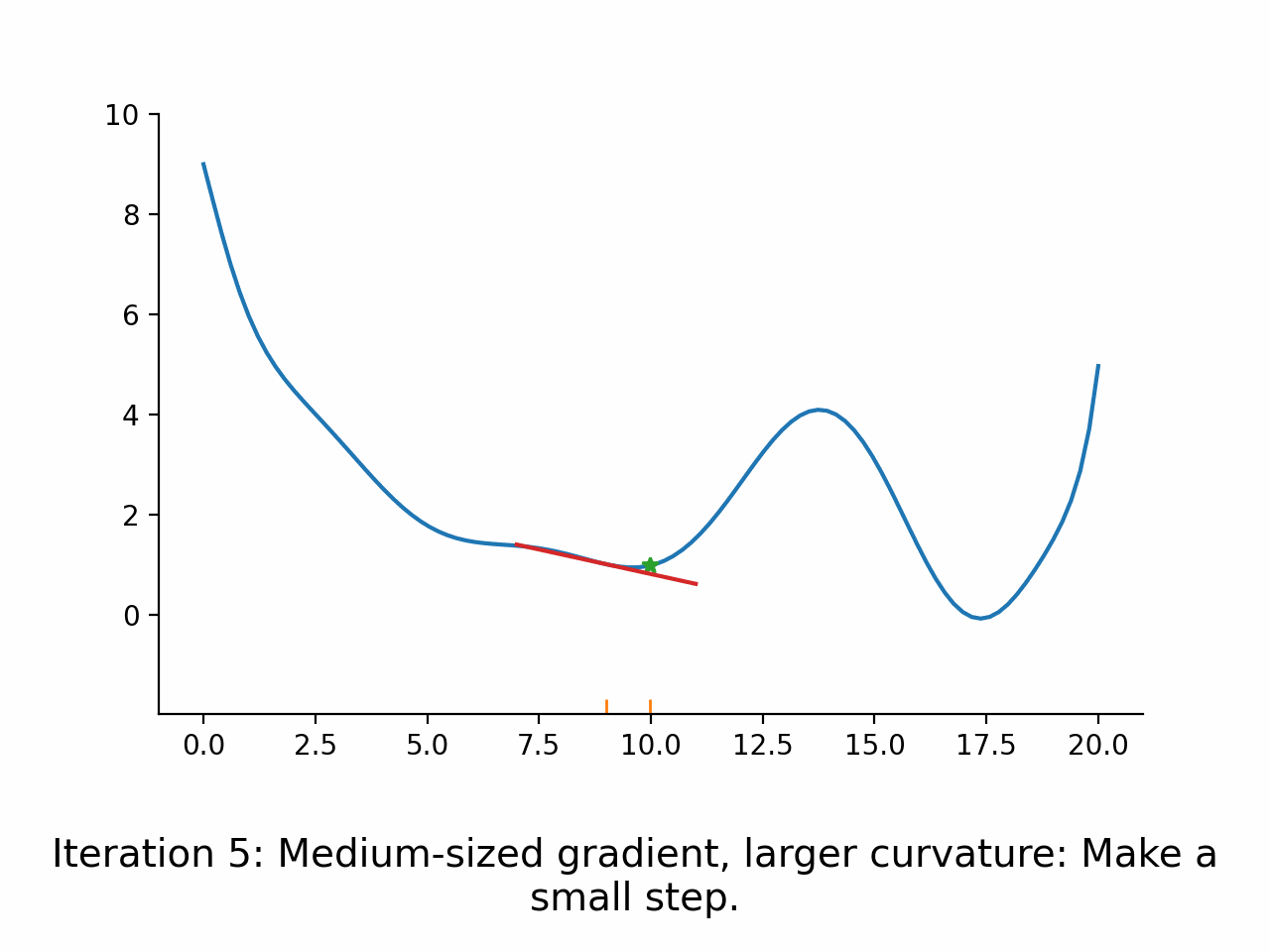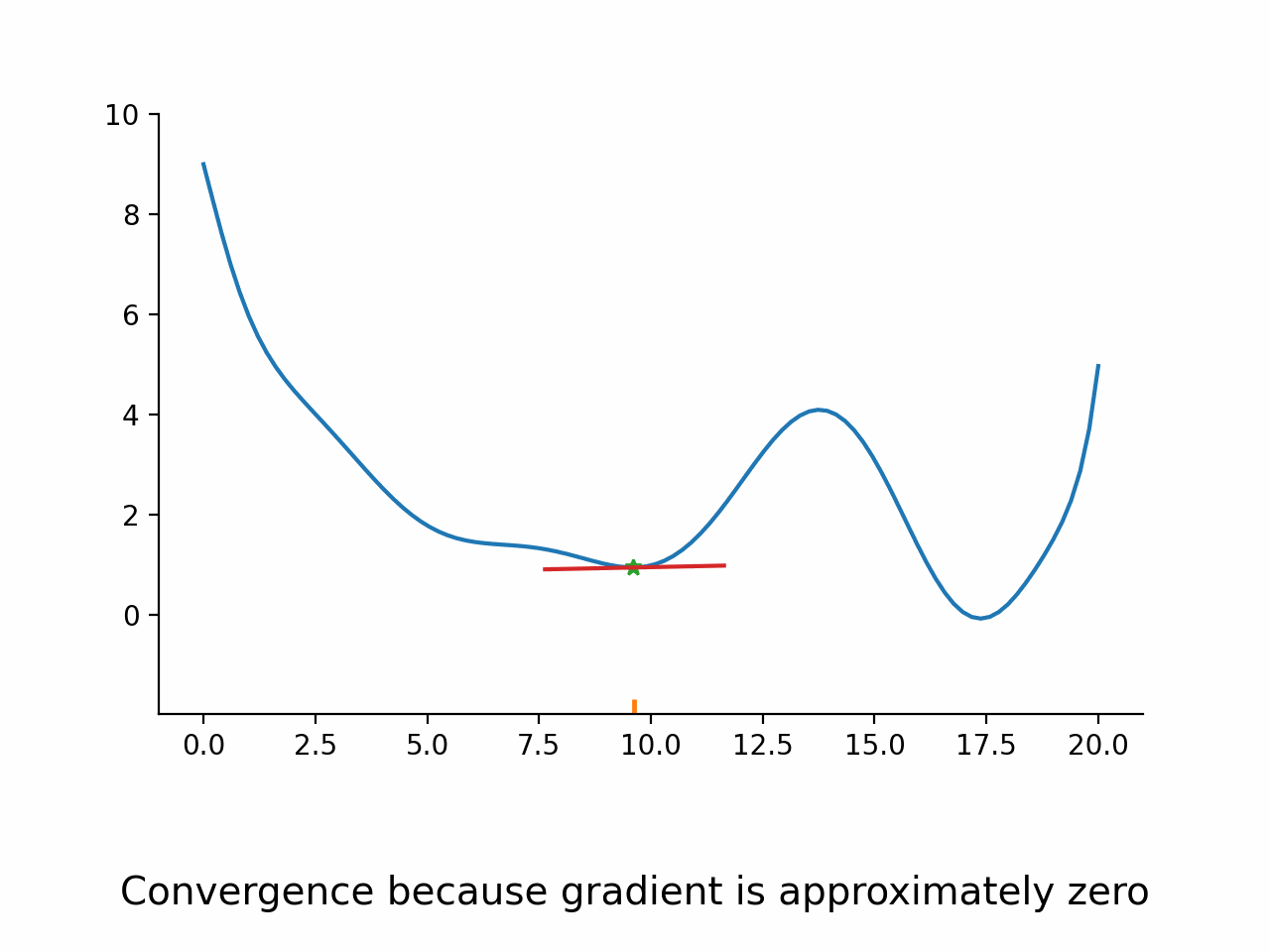
Convergence of a real algorithm#
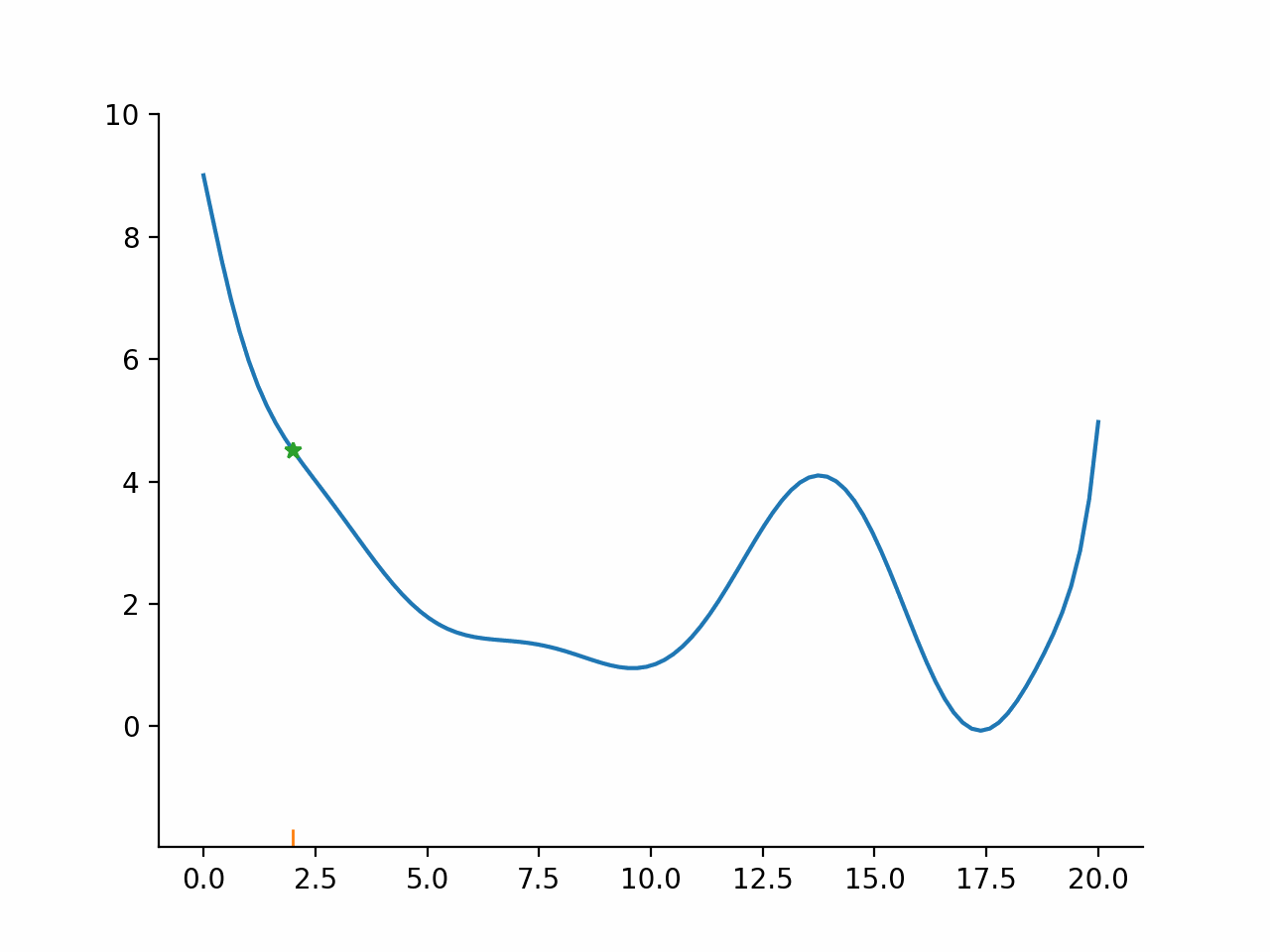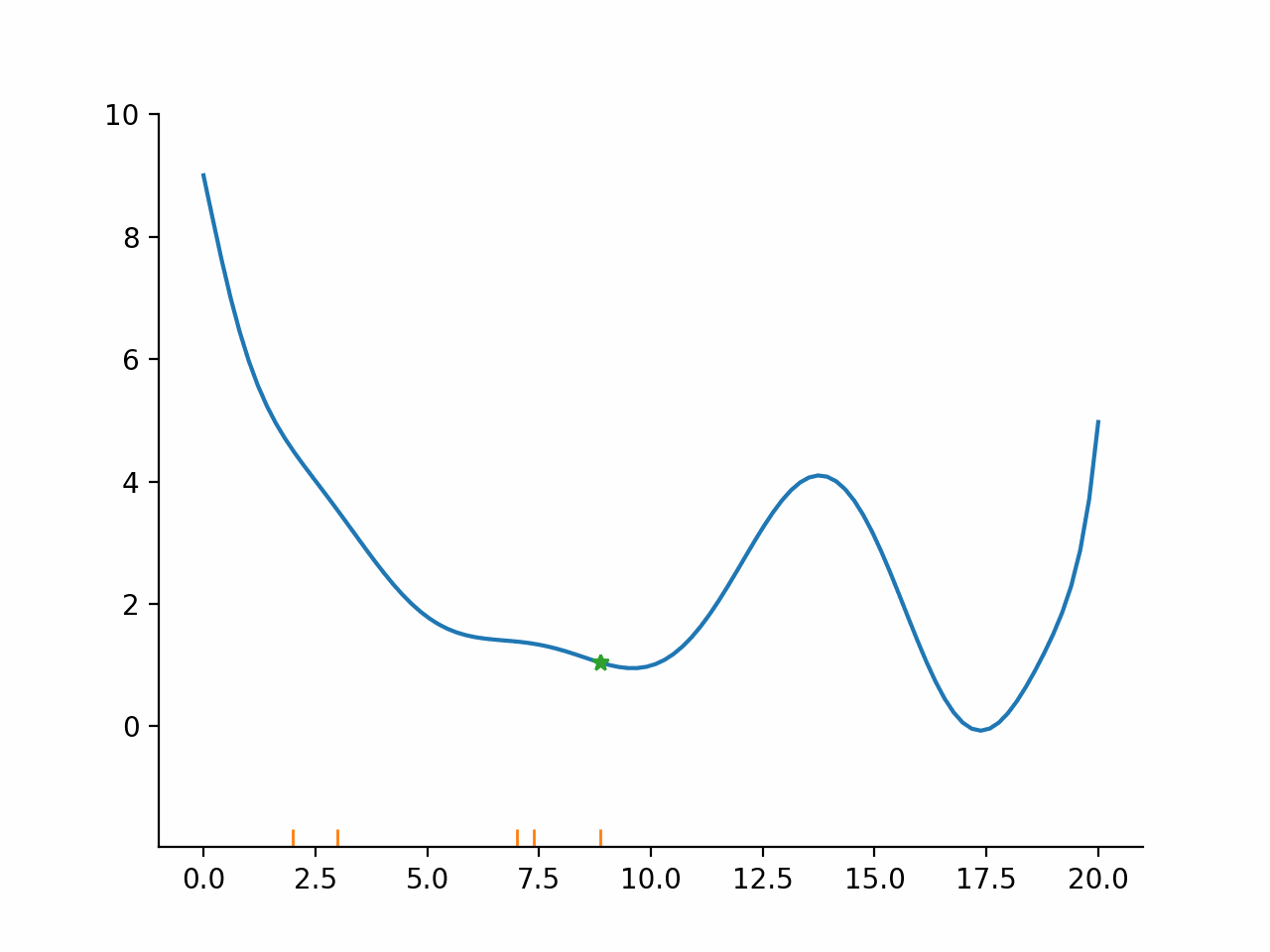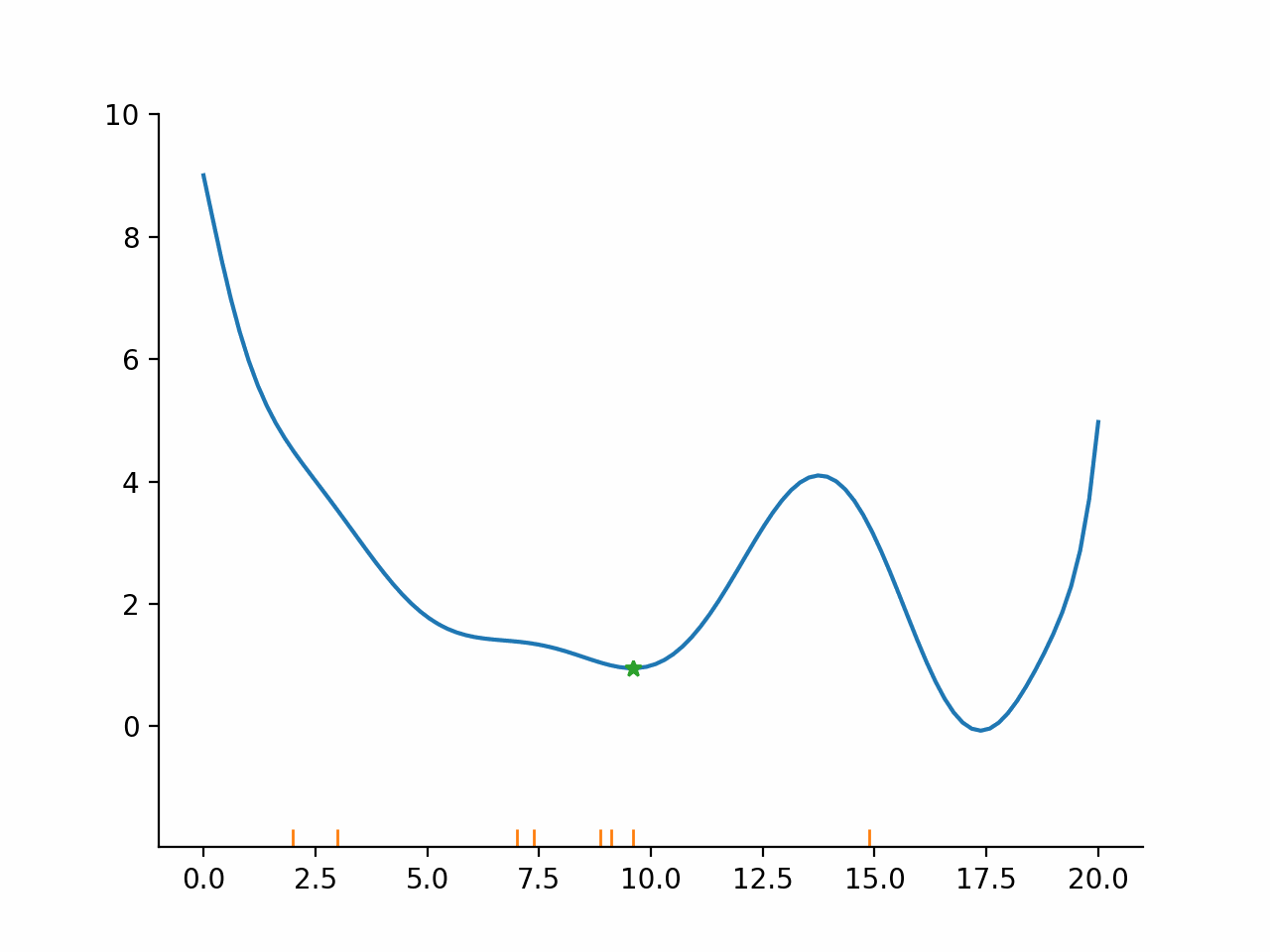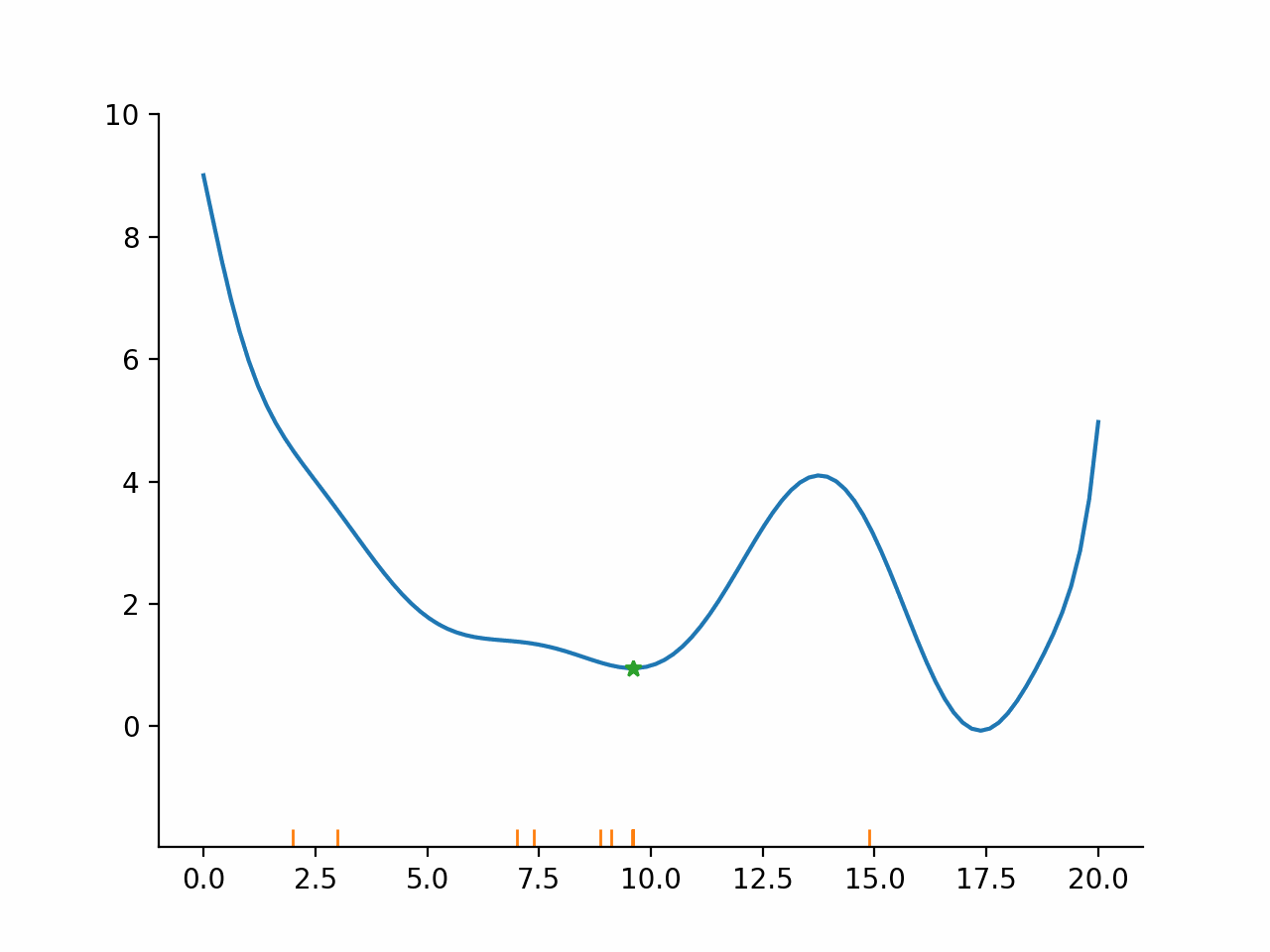
Derivative based trust-region algorithms#
Basic idea#
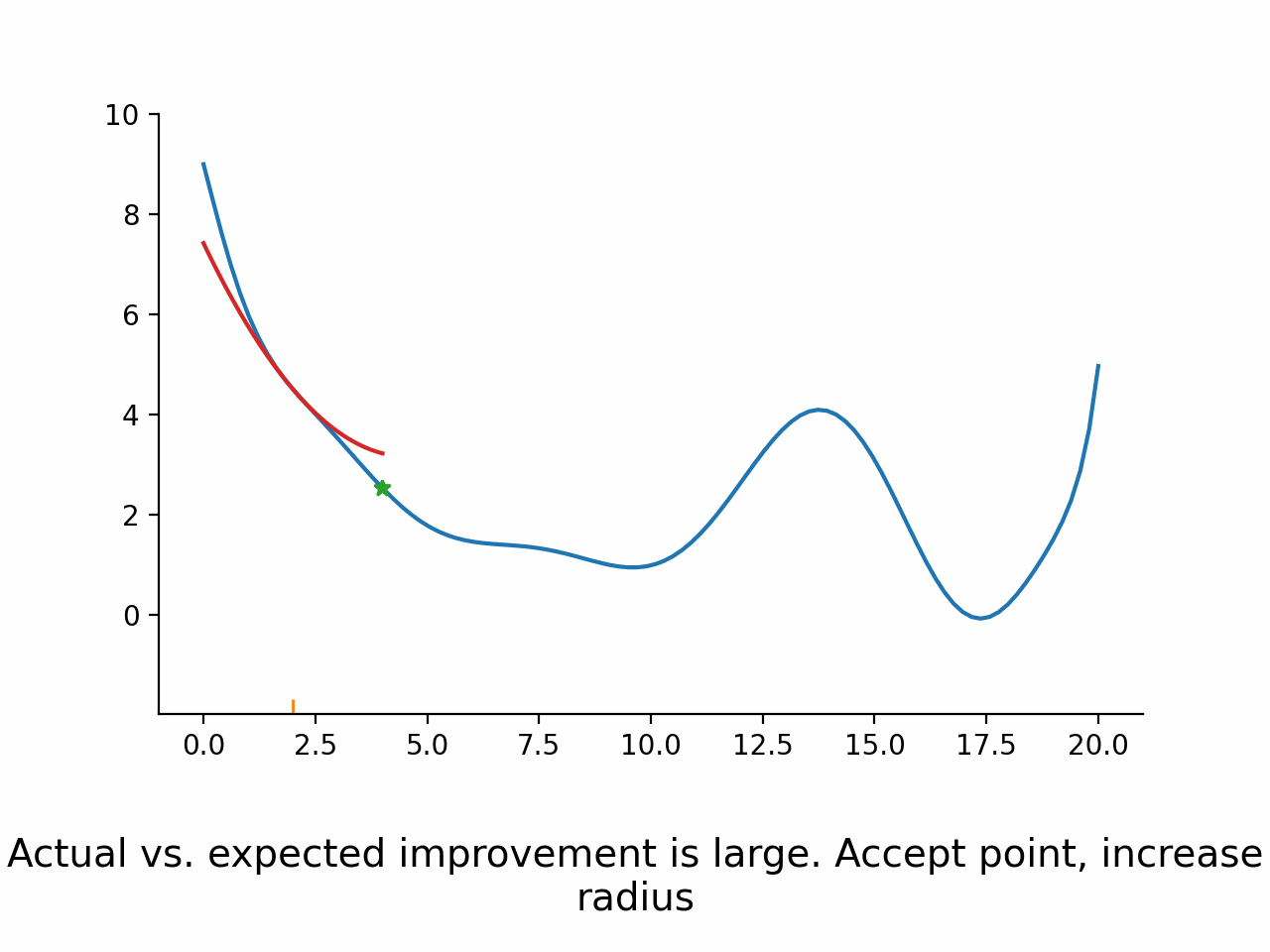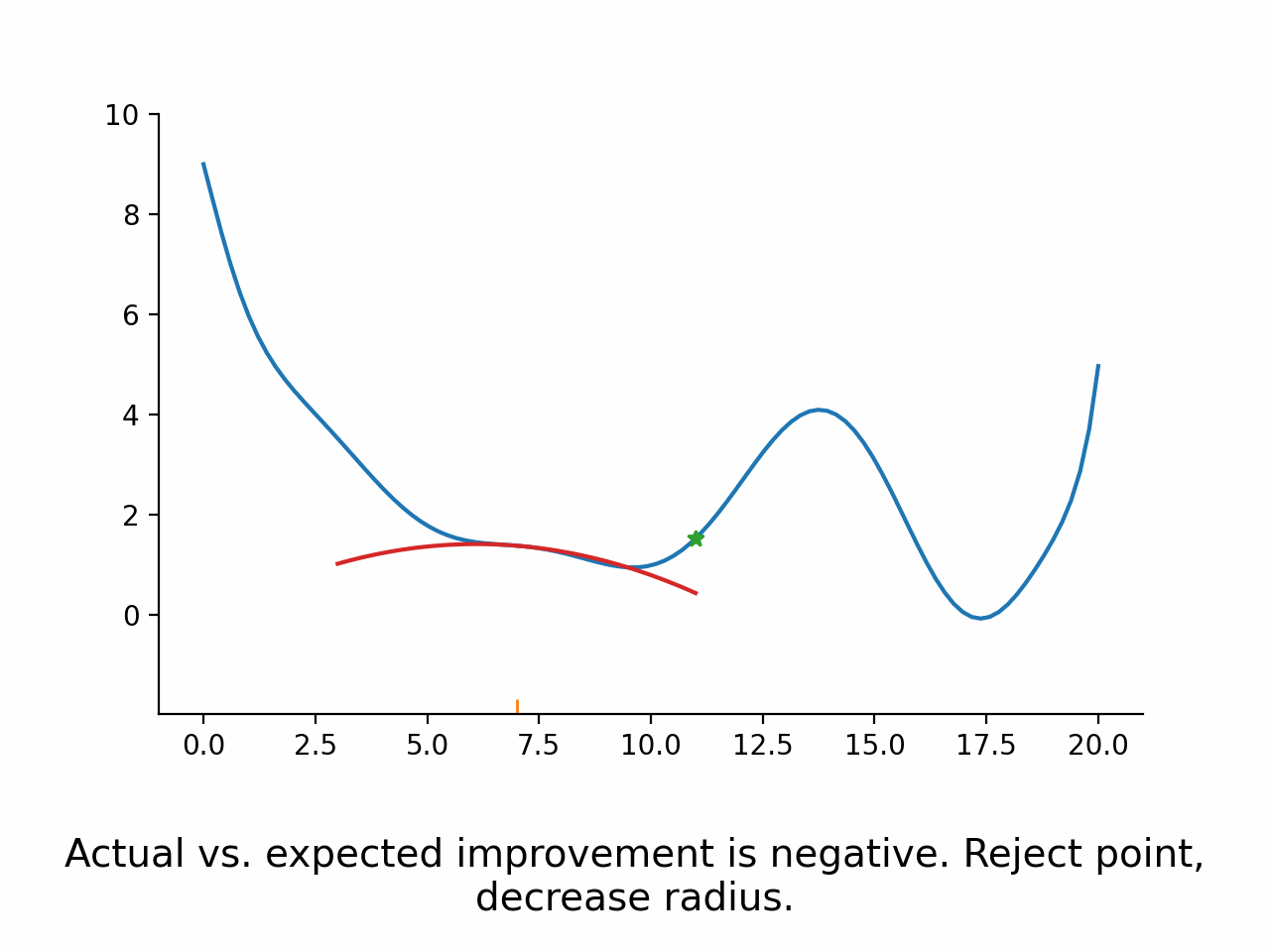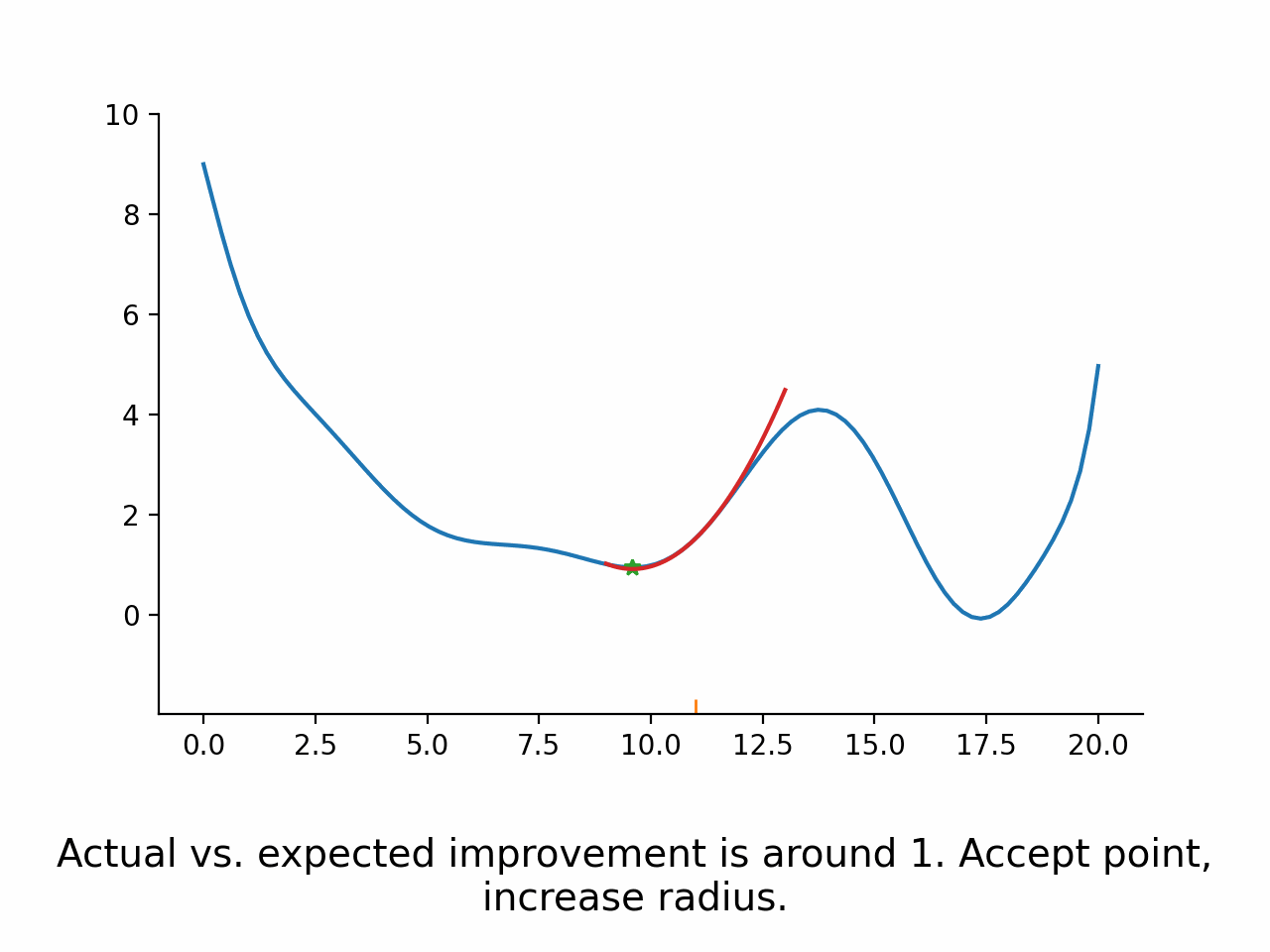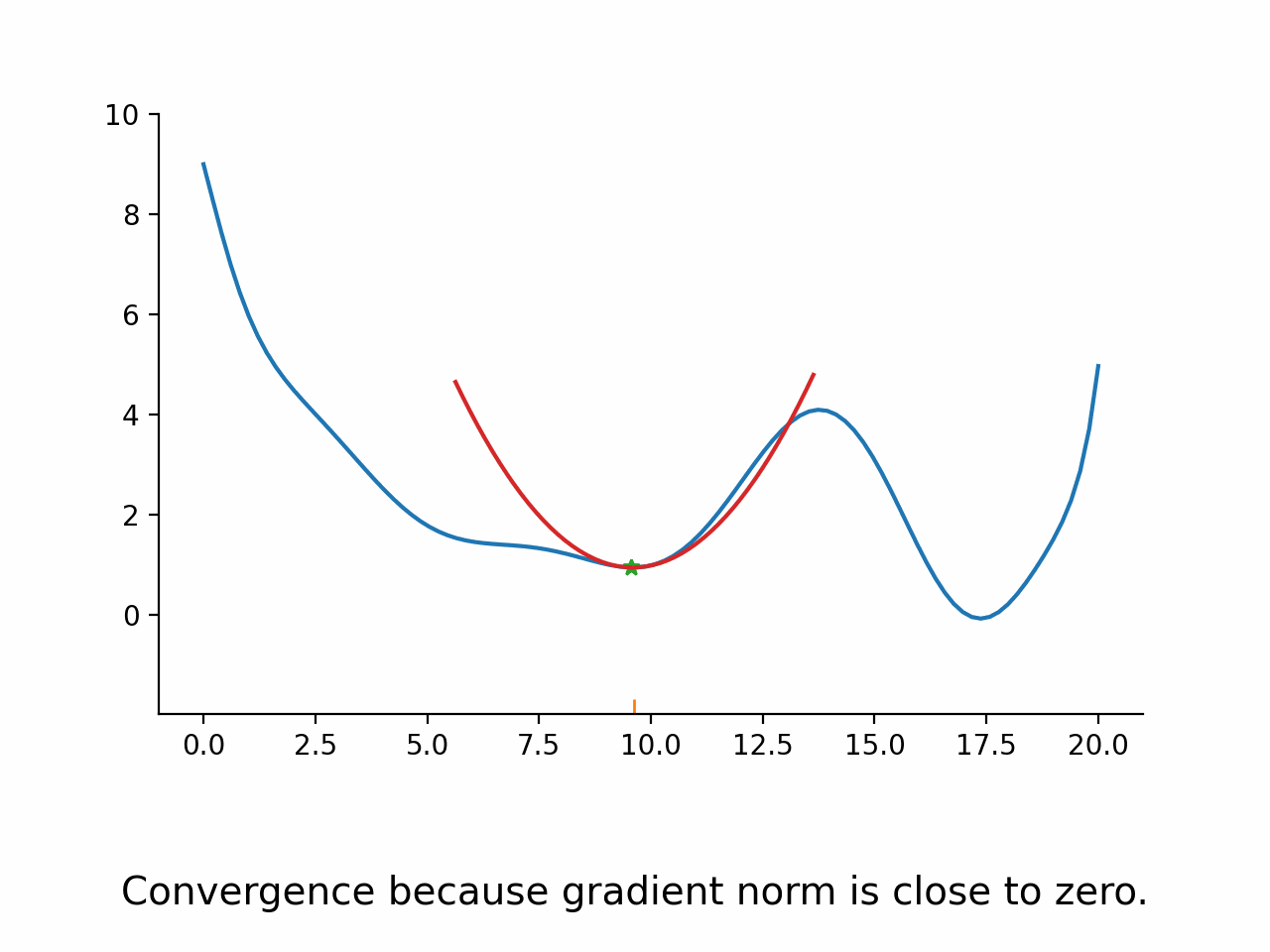
Fix a trust region radius
Construct a Taylor expansion of the function based on function value, gradient, and (approximation to) Hessian
Minimize the Taylor expansion within the trust region
Evaluate function again at the argmin of the Taylor expansion
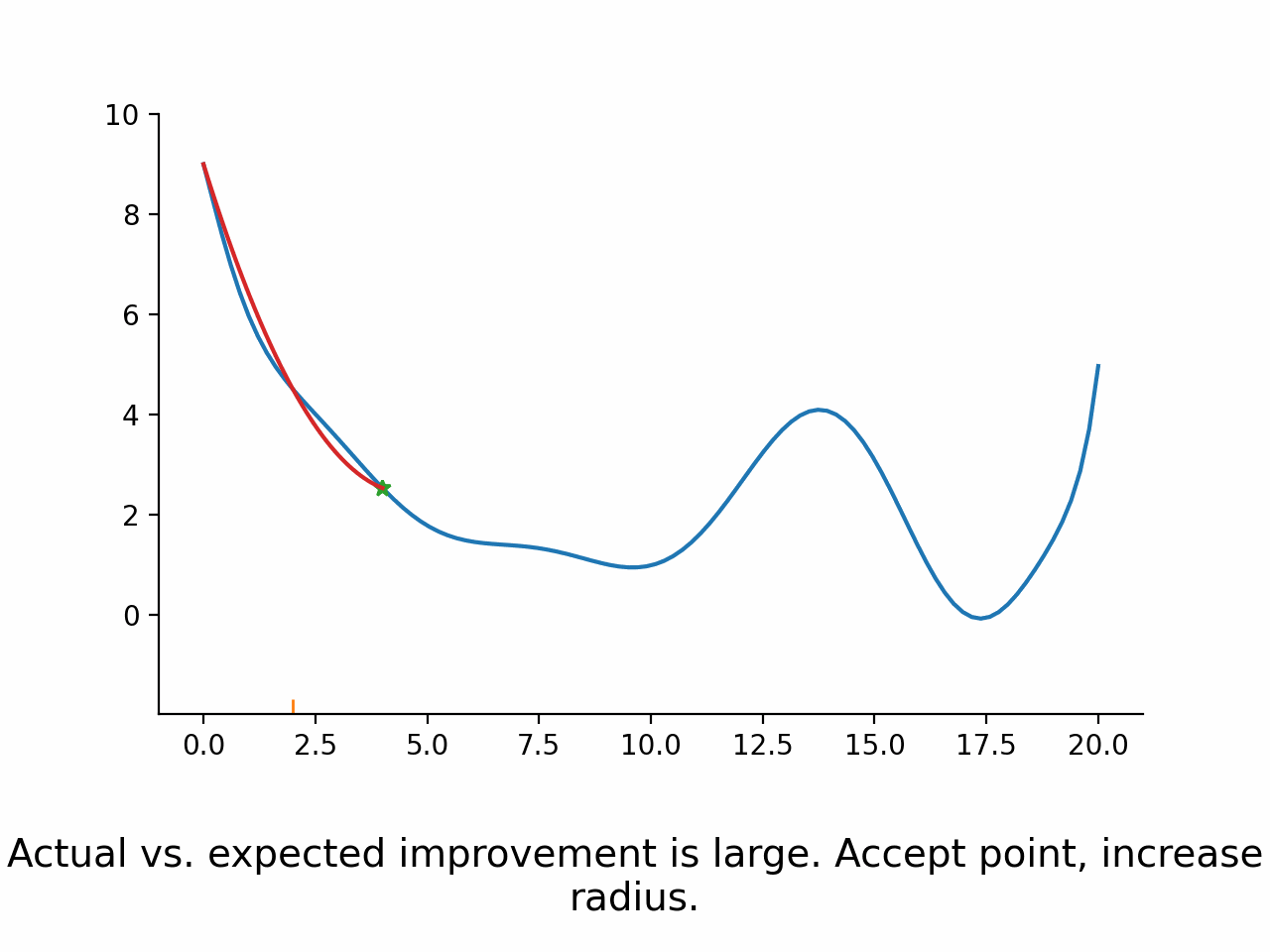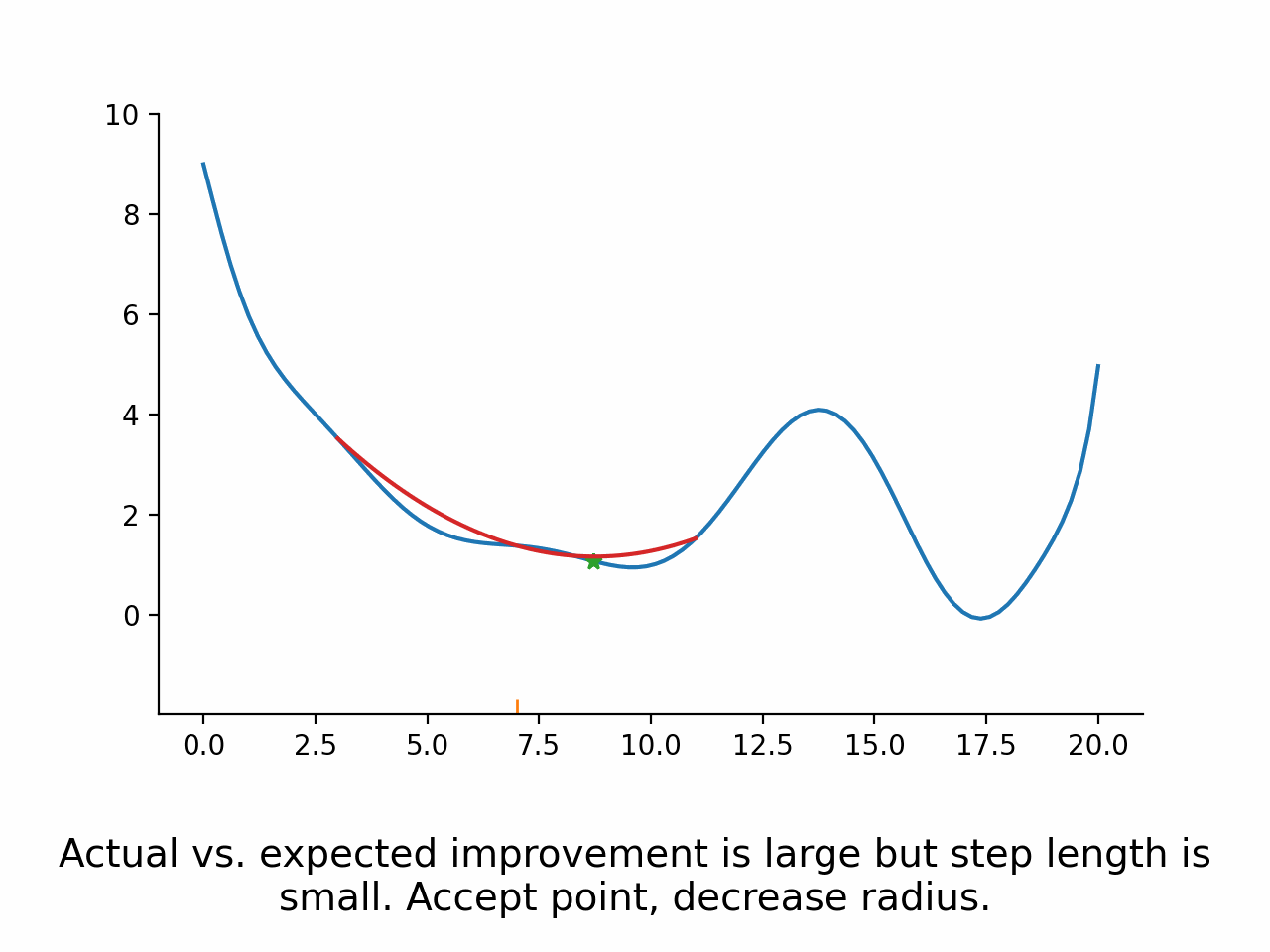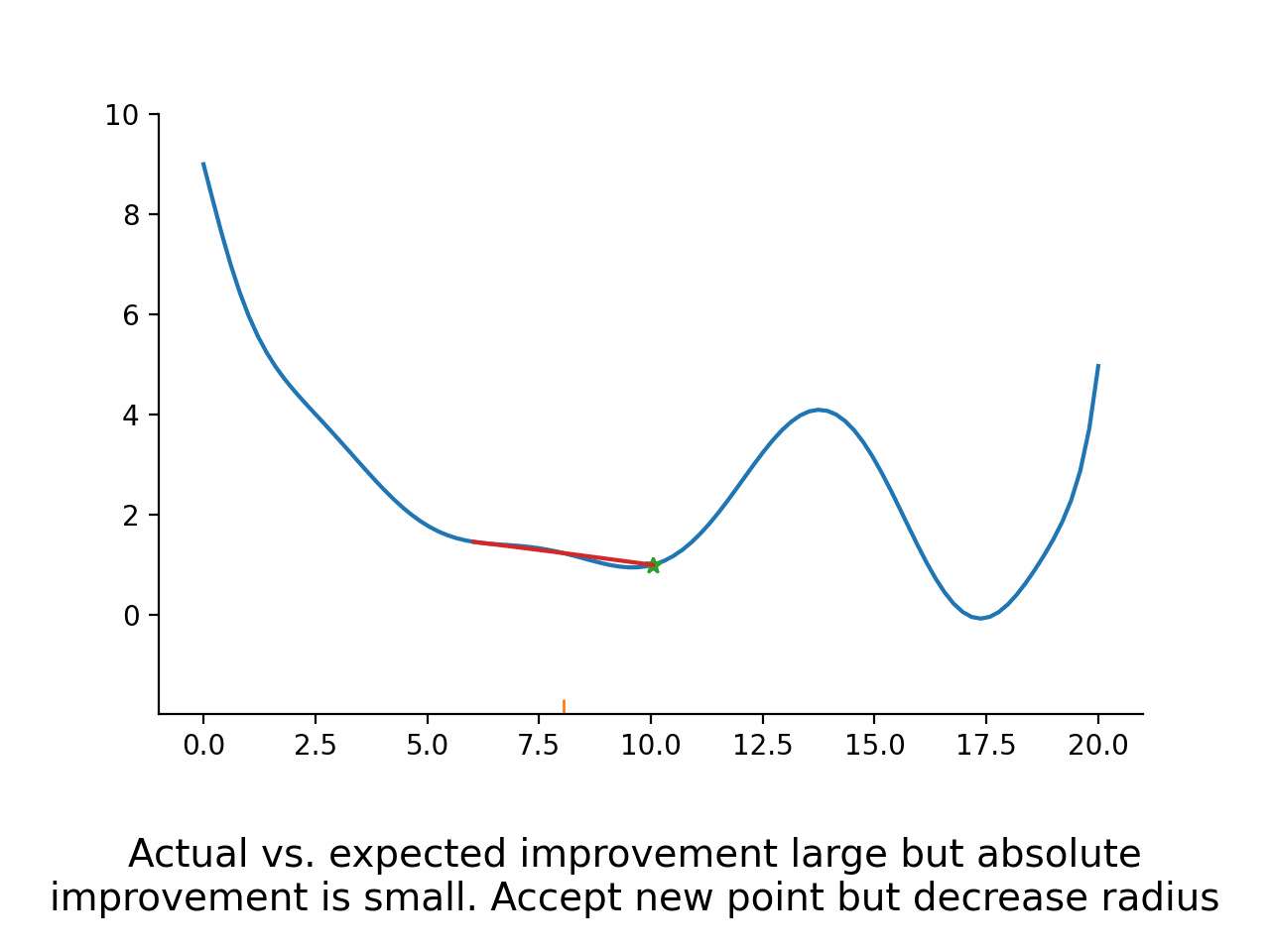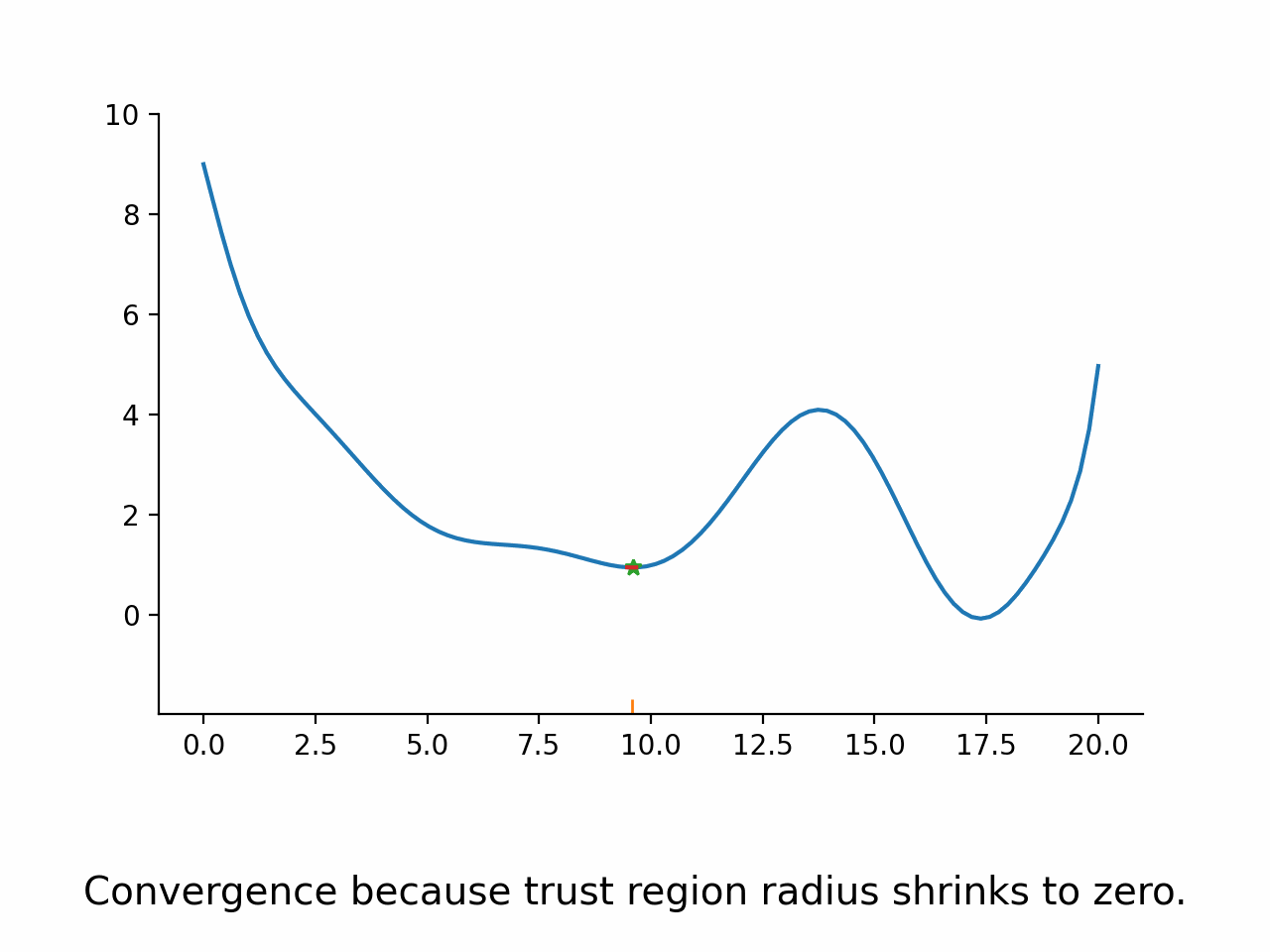
Compare expected and actual improvement
Accept the new parameters if actual vs. expected improvement is good enough.
Potentially modify the trust region radius
Go back to 2.
In other words, the algorithm first fixes a maximum step length (the trust region radius) and then figures out in which direction to go. If the surrogate model (usually a quadratic taylor expansion) approximates the function well, trust region algorithms can converge extremely fast. The main insight here is that evaluating the surrogate model is usually much cheaper than evaluating the actual criterion function and thus the trust region subproblem can be solved very fast.
As can be seen in the stylized implementation, the approximation does not actually have to be very good. The only thing that matters is that it points the optimizer in the right direction.
Stylized implementation#
Convergence of a real algorithm#

Derivative free trust region algorithms#
Basic Idea#
The basic idea is very similar to derivative based trust region algorithms. The only difference is that instead of a Taylor approximation which requires derivatives, we need to come up with another type of surrogate model.
In order to fit this model, the algorithm evaluates the criterion function at a few points inside the trust region. Depending on how many points those are the surrogate model is a interpolation or regression model. If there are very few points it might even be an underdetermined interpolation model. In that case some kind of regularization is needed.
Note that for differentiable functions without closed form derivatives, one way to define the surrogate model would be a Taylor approximation calculated from numerical derivatives. However, this would be a rather inefficient choice because points that are spaced more evenly throughout the trust region provide more information about the criterion function than the numerical derivatives.
Stylized implementation#
Convergence of a real algorithm#
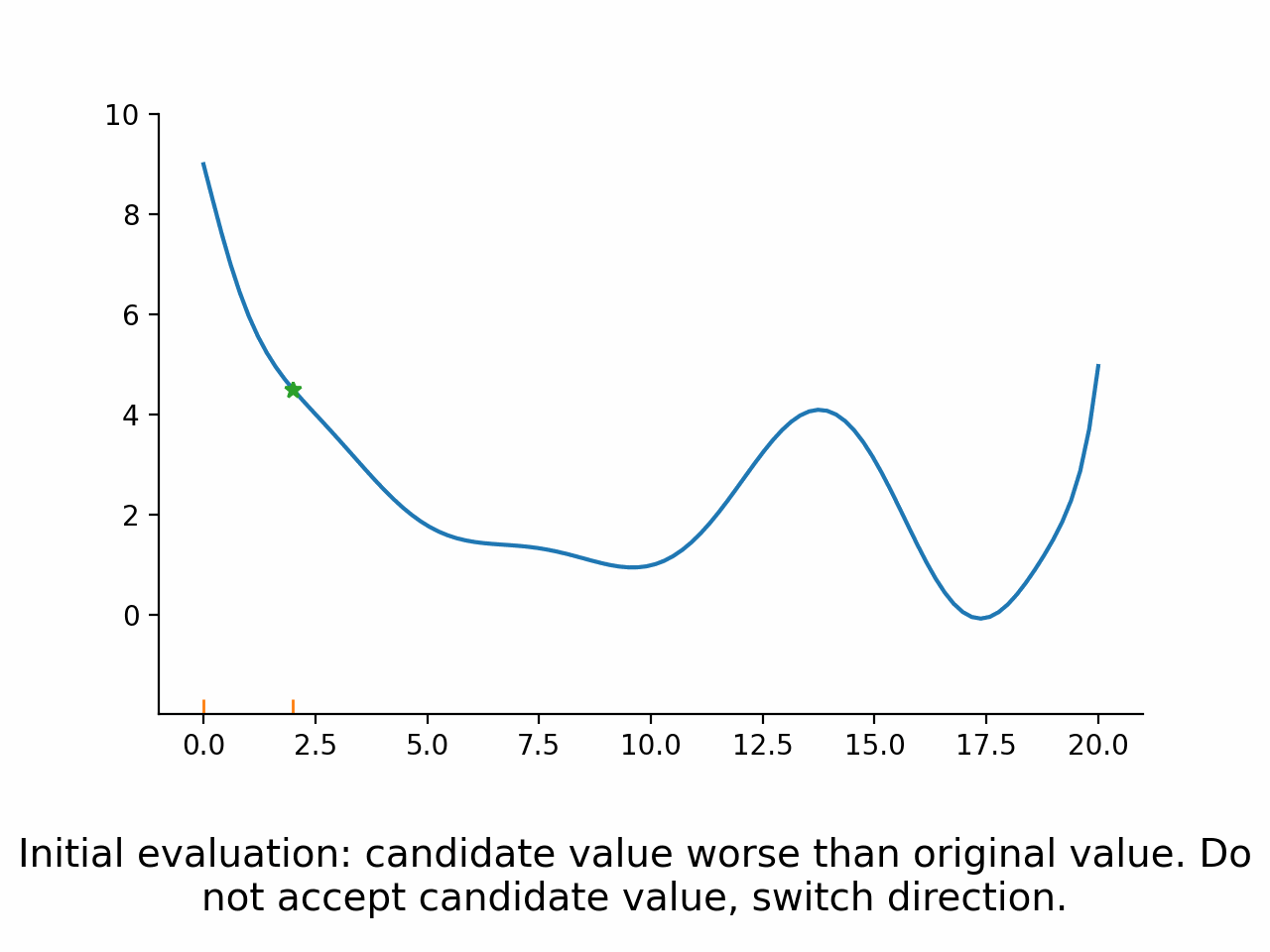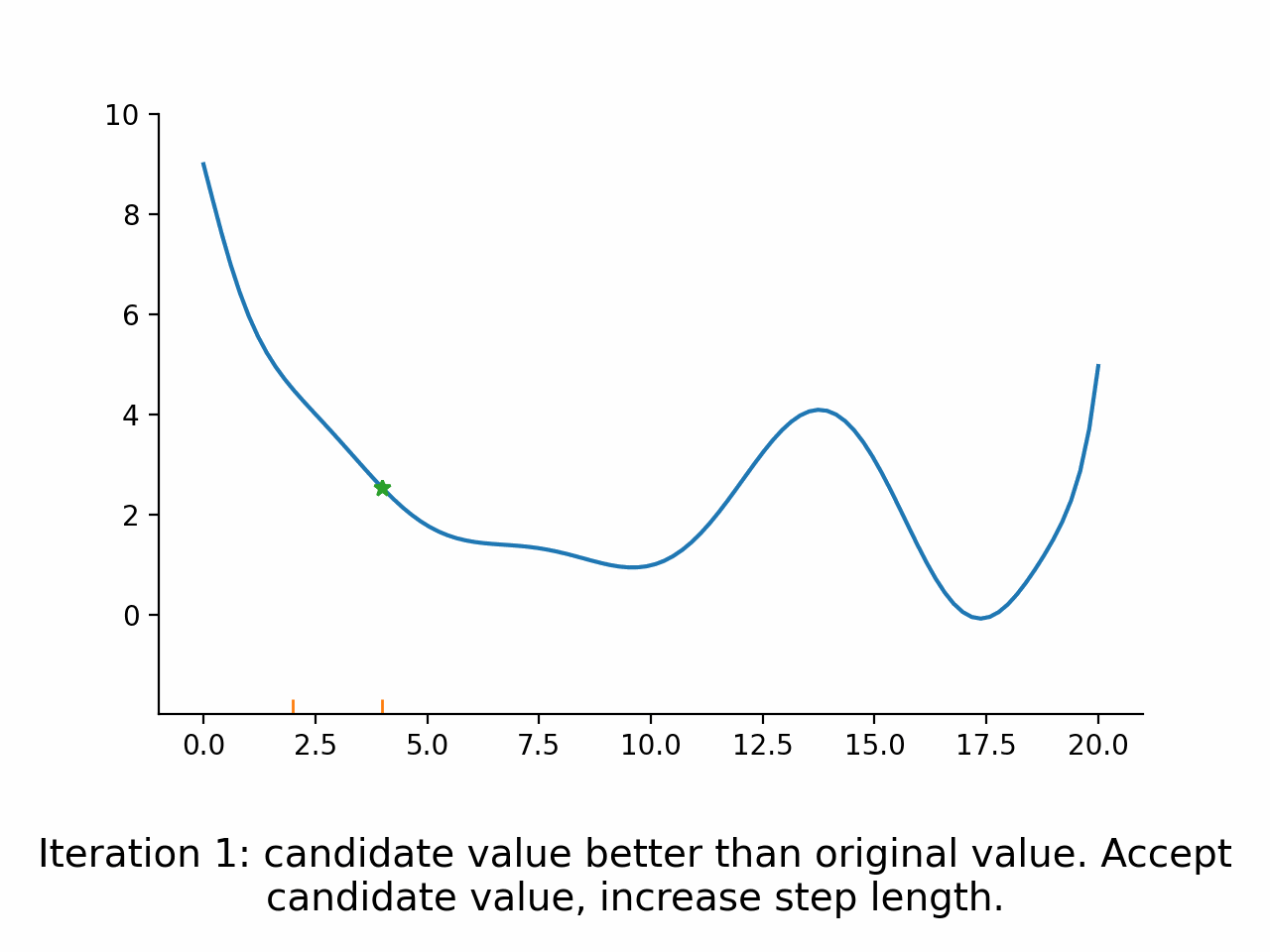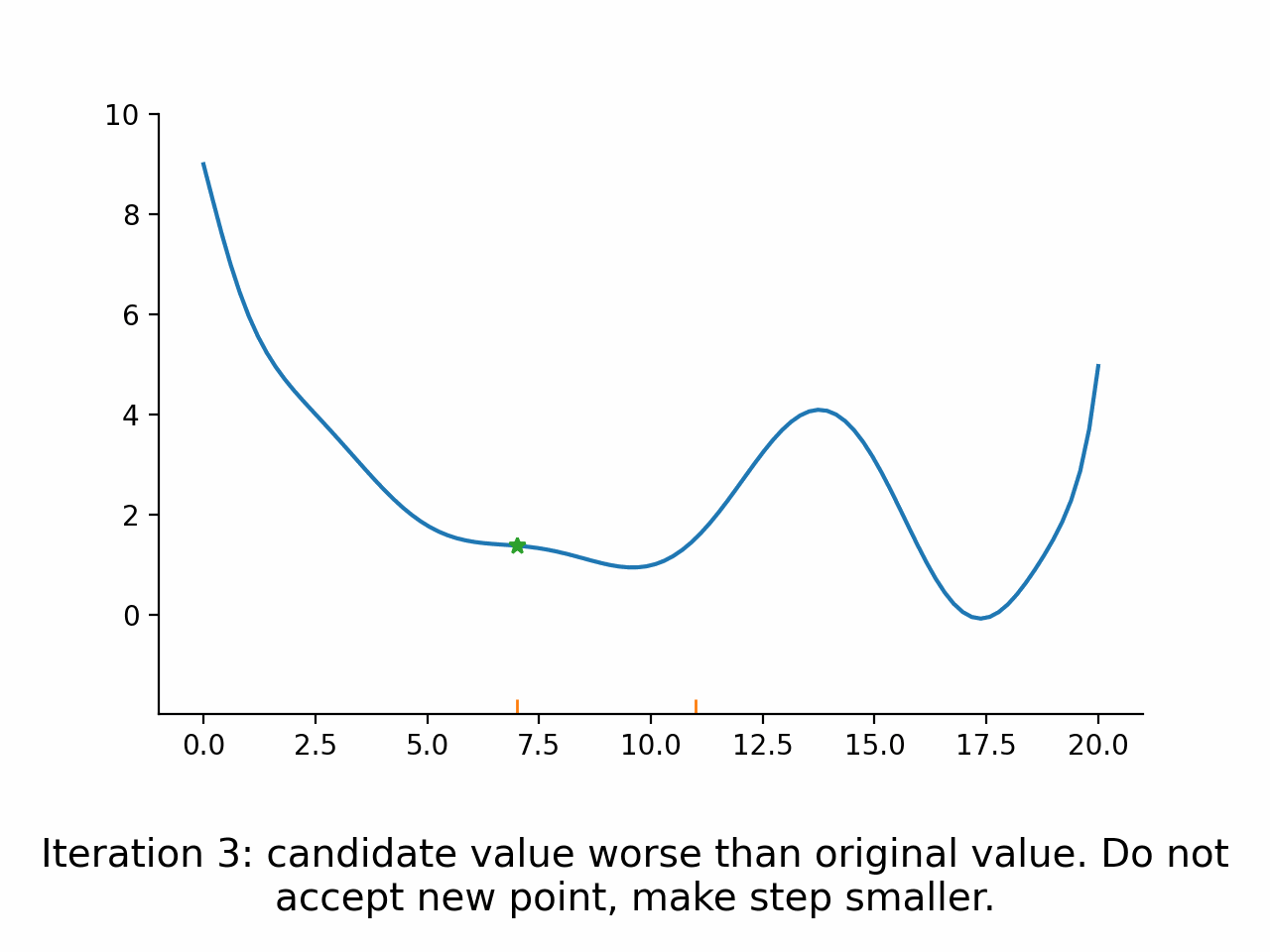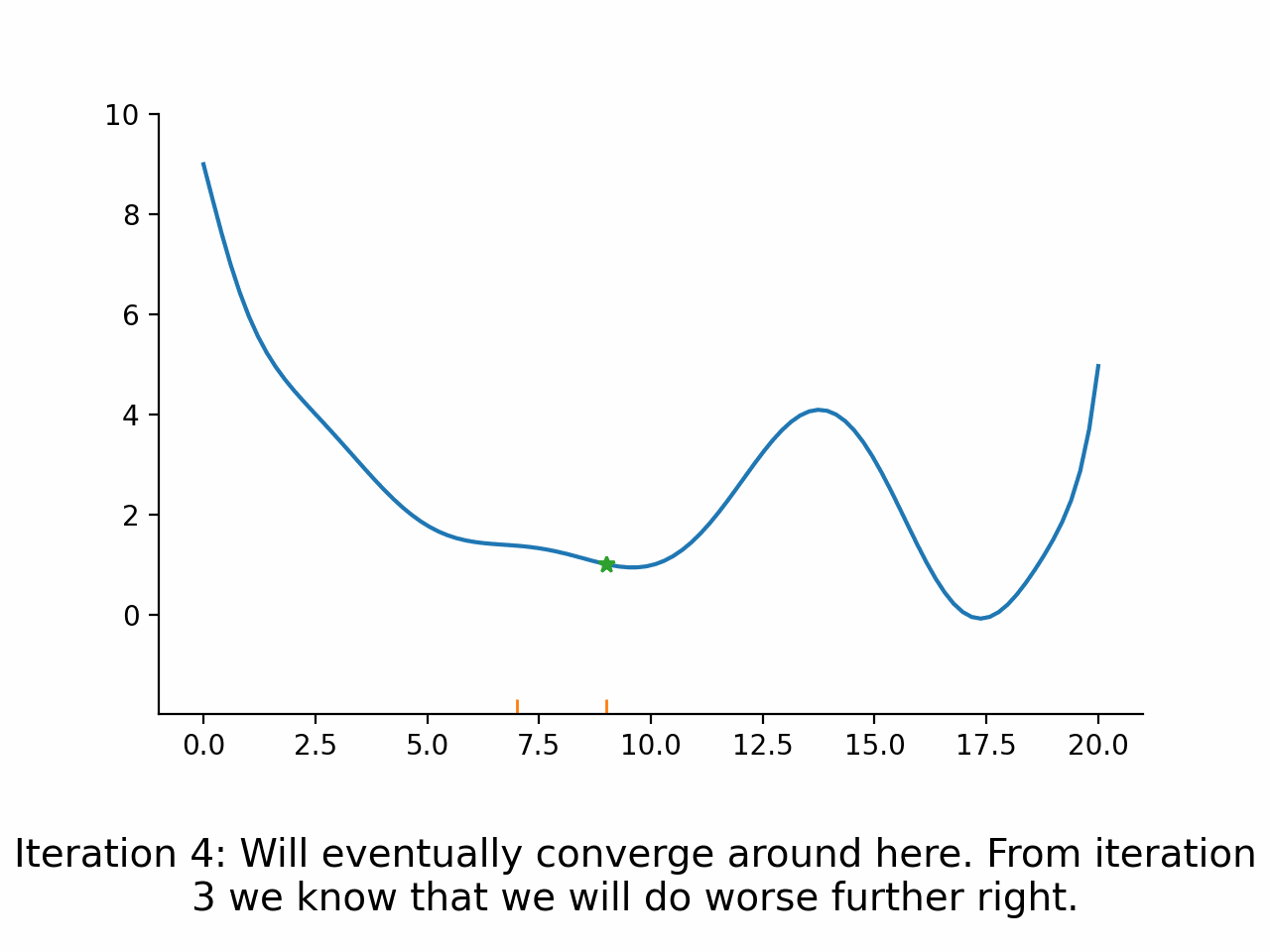
Derivative free direct search algorithms#
Basic Idea#
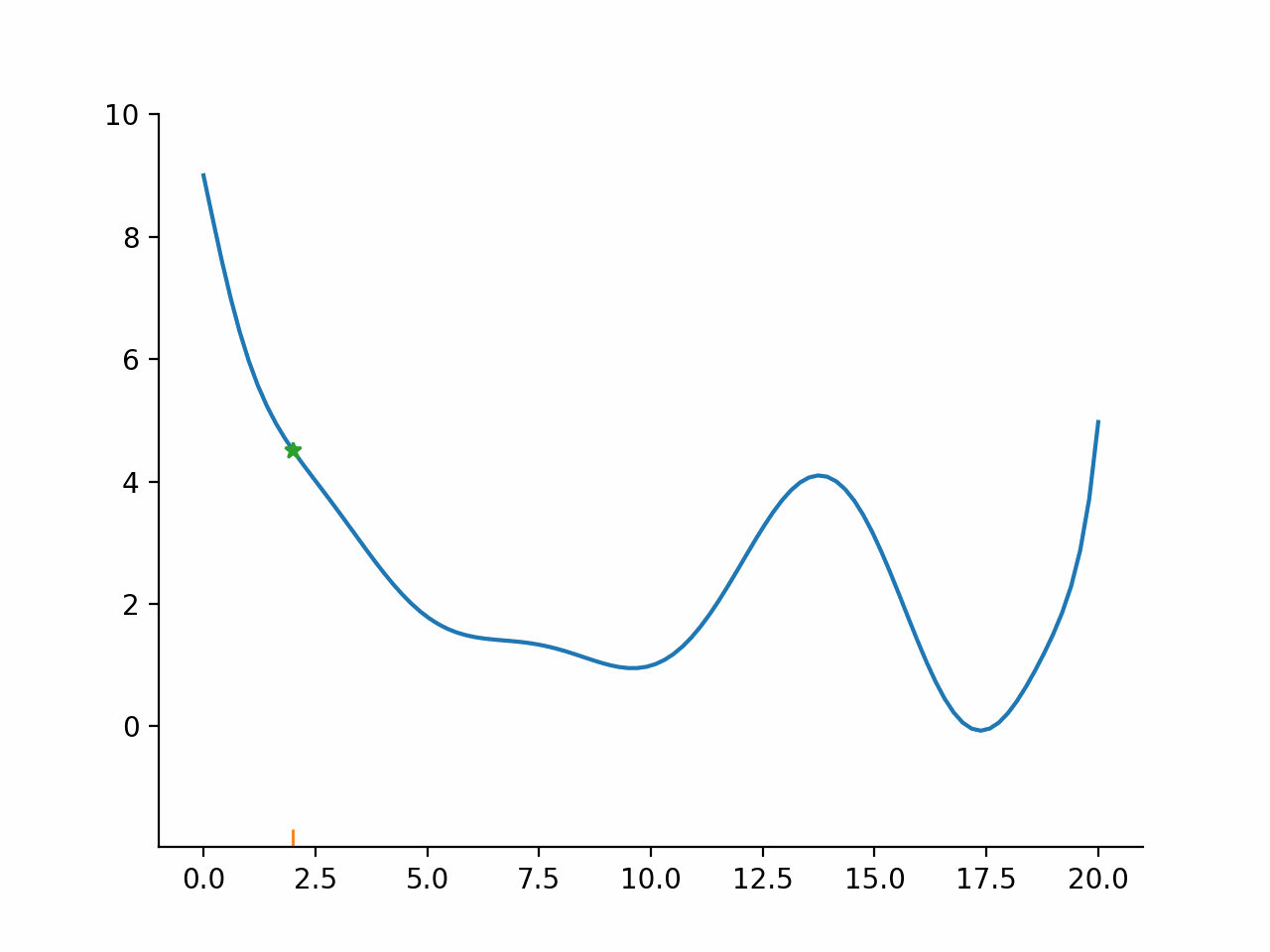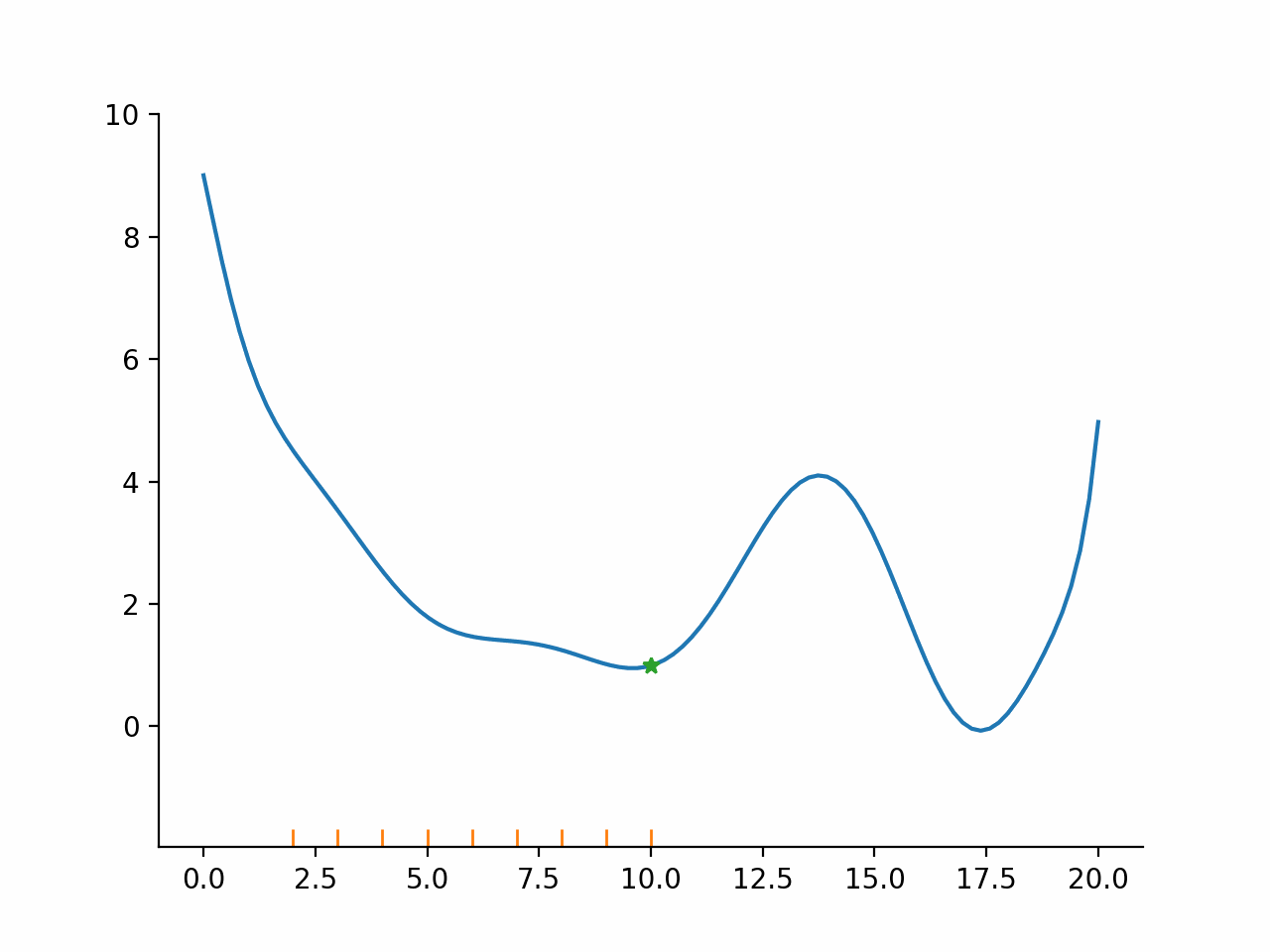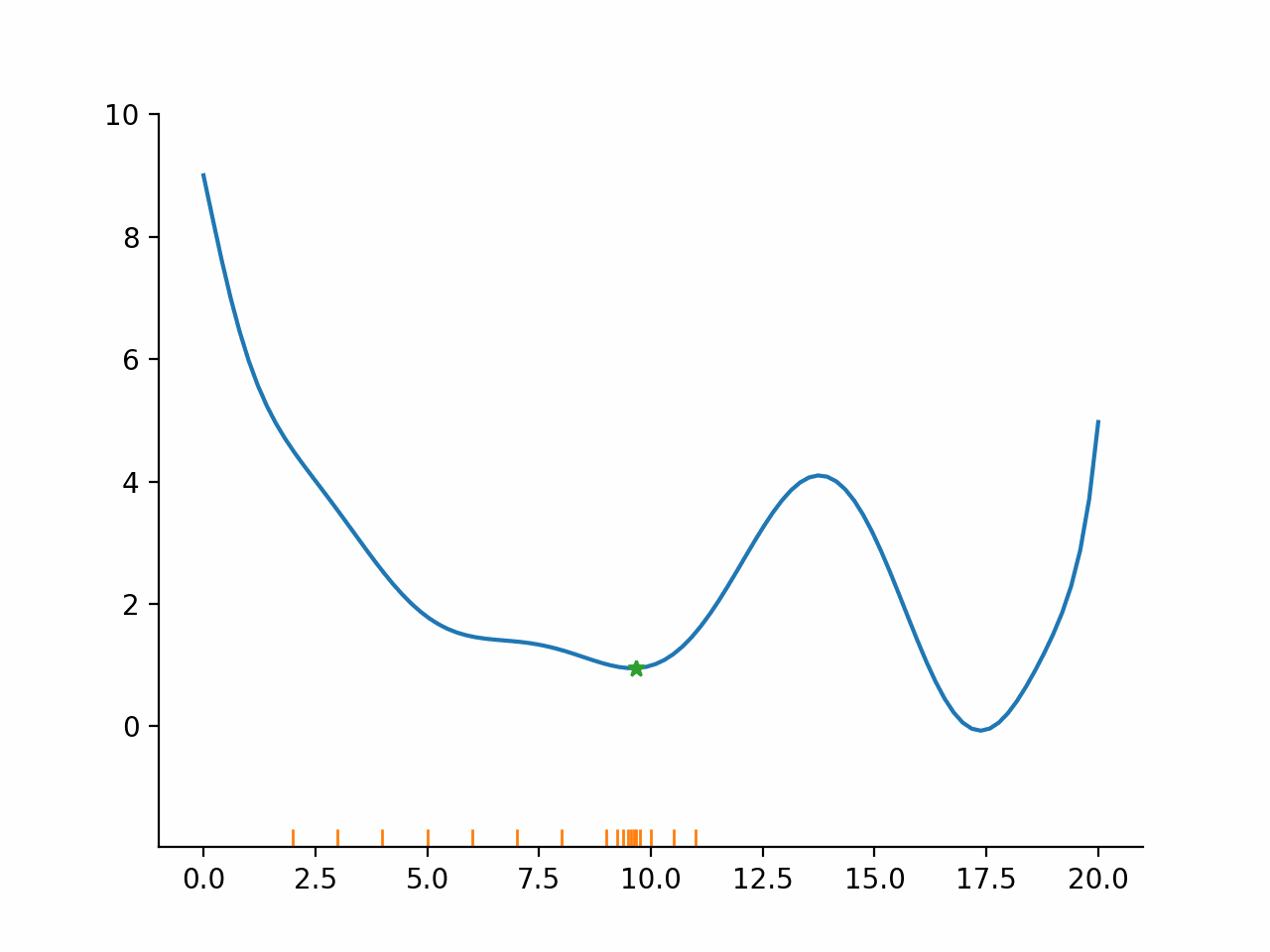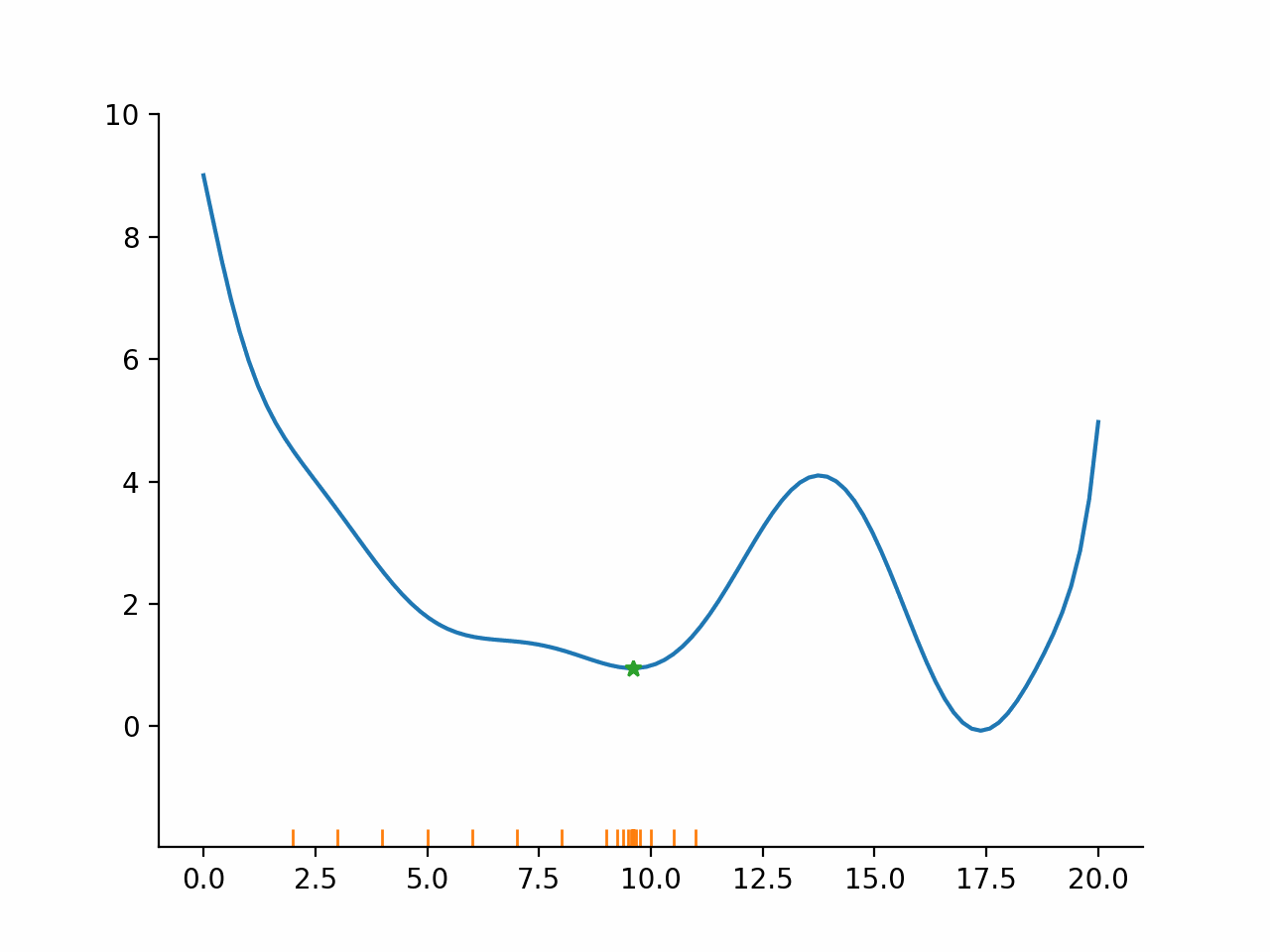
Evaluate function at points lying in a fixed pattern around the current point
Accept the best point as new current point
Potentially modify the size or spread of the pattern
Go back to 1.
Direct search algorithms are also called pattern search algorithms. They can typically deal well with small amounts of noise, because only the ordering of function values is used, not the magnitudes. However, they are relatively slow compared to the other algorithms.
Stylized implementation#
Convergence of a real algorithm#